爬虫入门
前情摘要
一、web请求全过程剖析
我们浏览器在输入完网址到我们看到网页的整体内容, 这个过程中究竟发生了些什么?
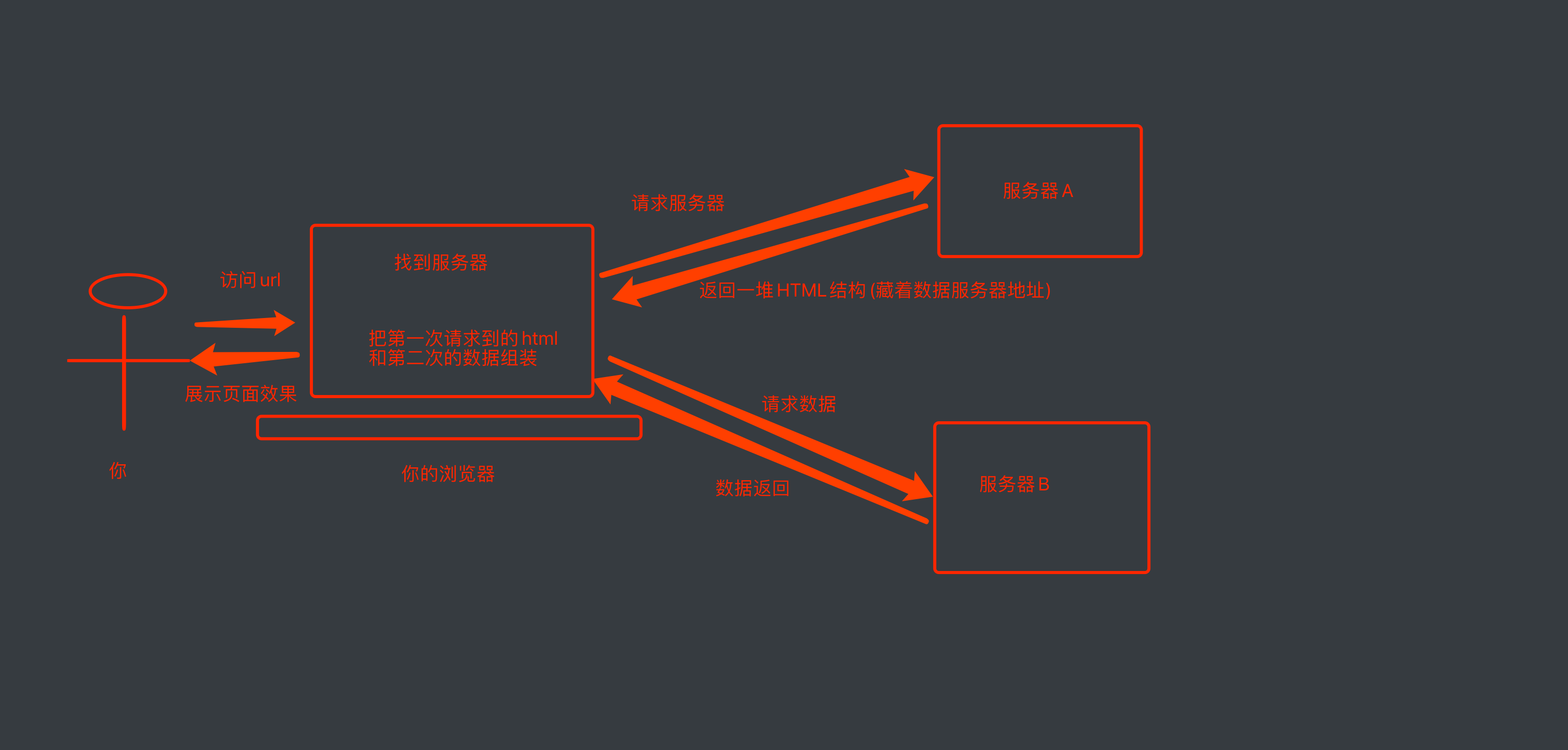
我们看一下一个浏览器请求的全过程
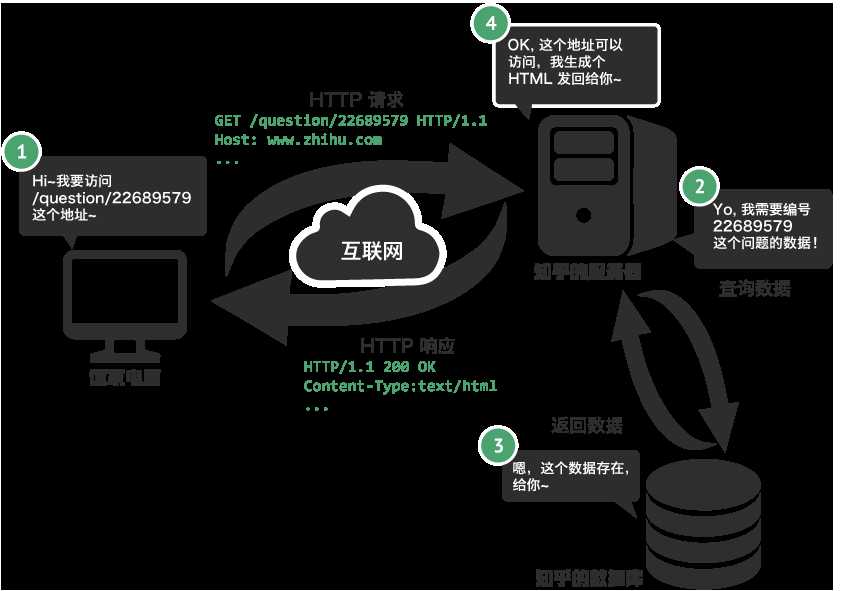
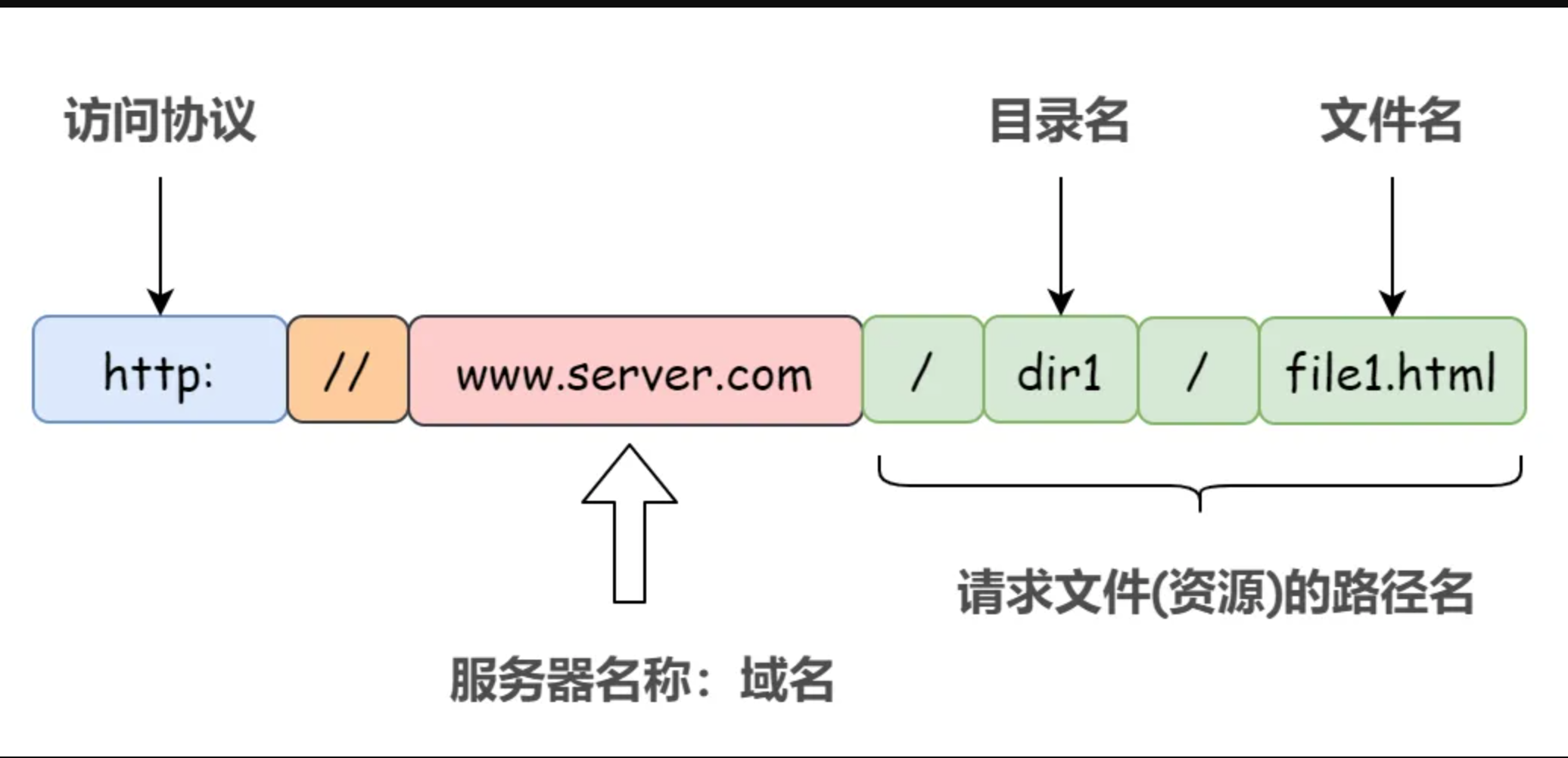
接下来就是一个比较重要的事情了. 所有的数据都在页面源代码里么? 非也~ 这里要介绍一个新的概念
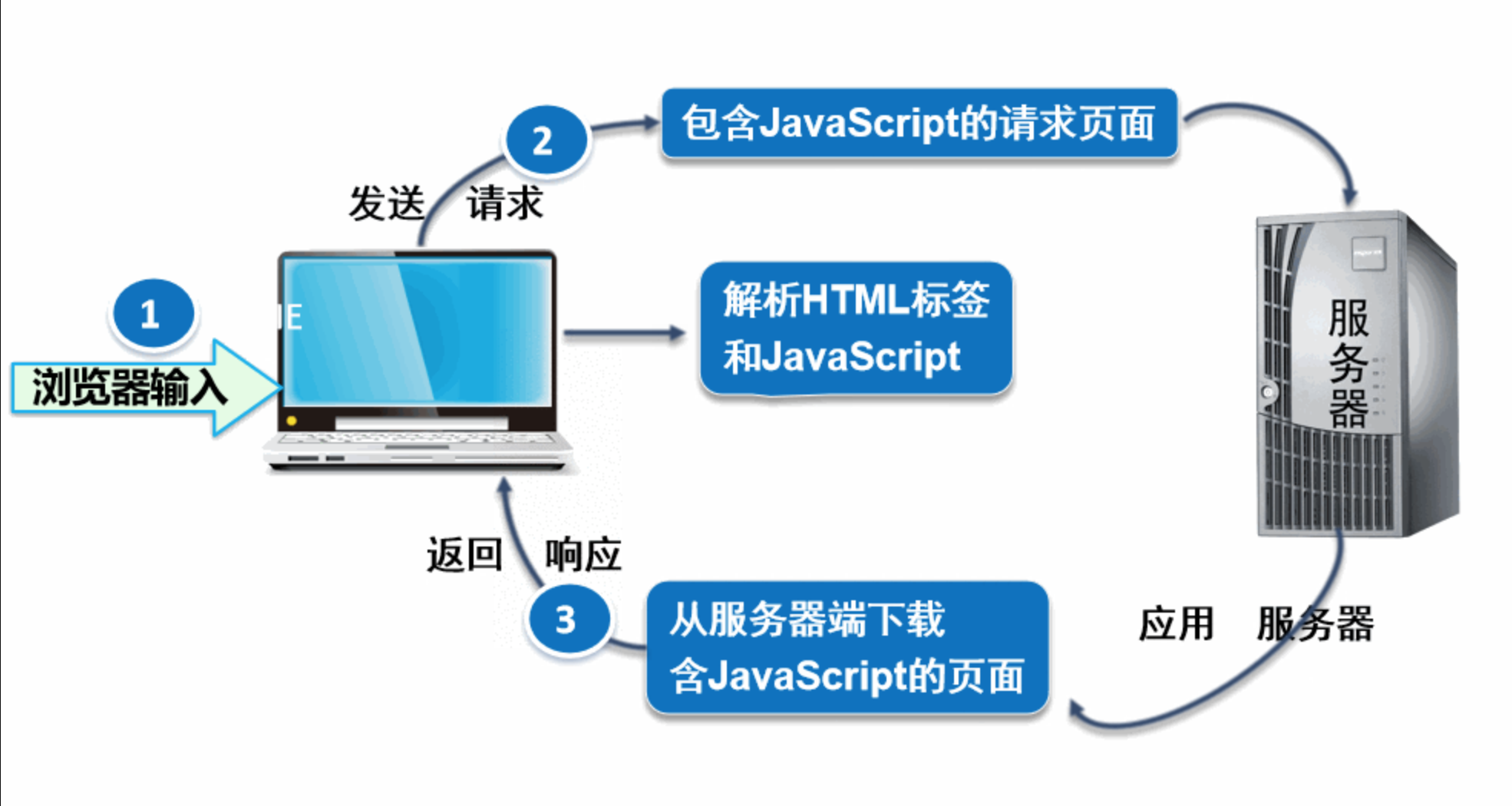
那就是页面渲染数据的过程, 我们常见的页面渲染过程有两种,
服务器渲染, 你需要的数据直接在页面源代码里能搜到
这个最容易理解, 也是最简单的. 含义呢就是我们在请求到服务器的时候, 服务器直接把数据全部写入到html中, 我们浏览器就能直接拿到带有数据的html内容. 比如,
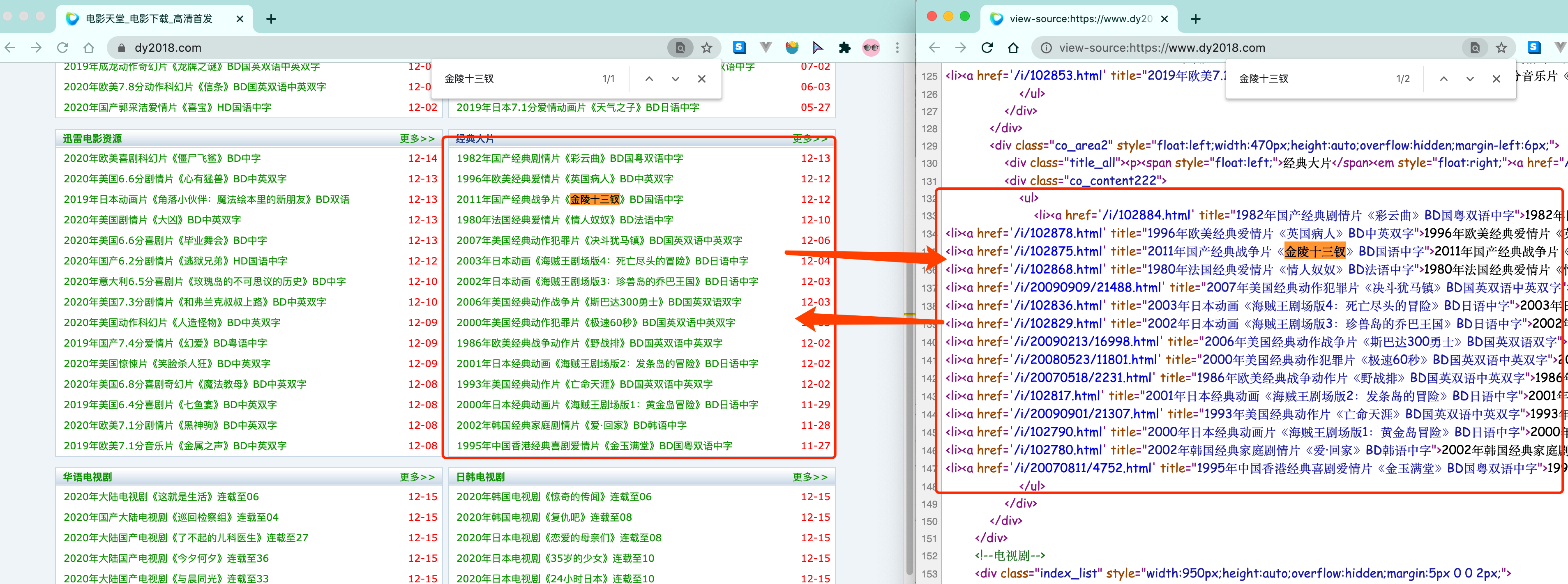
由于数据是直接写在html中的, 所以我们能看到的数据都在页面源代码中能找的到的.
这种网页一般都相对比较容易就能抓取到页面内容.
前端JS渲染, 你需要的数据在页面源代码里搜不到
这种就稍显麻烦了. 这种机制一般是第一次请求服务器返回一堆HTML框架结构. 然后再次请求到真正保存数据的服务器, 由这个服务器返回数据, 最后在浏览器上对数据进行加载. 就像这样:
js渲染代码(示例)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>案例:动态渲染页面</title> <style> table{ width: 300px; text-align: center; } </style> </head> <body> <table border="1" cellspacing="0"> <thead> <tr> <th>ID</th> <th>姓名</th> <th>年龄</th> </tr> </thead> <tbody> <!-- js渲染--> </tbody> </table> <script> //提前准备好的数据 var users = [ {id: 1, name: '张三', age: 18}, {id: 2, name: '李四', age: 28}, {id: 3, name: '王麻子', age: 38} ] //获取tbody标签 var tbody = document.querySelector('tbody') //1.循环遍历users数据 users.forEach(function (item) { //这里的item 就是数组中的每一个对象 console.log(item) //2. 每一个对象生成一个tr标签 var tr = document.createElement('tr') //循环遍历item for(var key in item){ //生成td标签 var td = document.createElement('td') td.innerHTML = item[key] //5.把td 插入到tr内部 tr.appendChild(td) } //把本次的tr插入到tbody的内部 tbody.appendChild(tr) }) </script> </body> </html>
这样做的好处是服务器那边能缓解压力. 而且分工明确. 比较容易维护. 典型的有这么一个网页
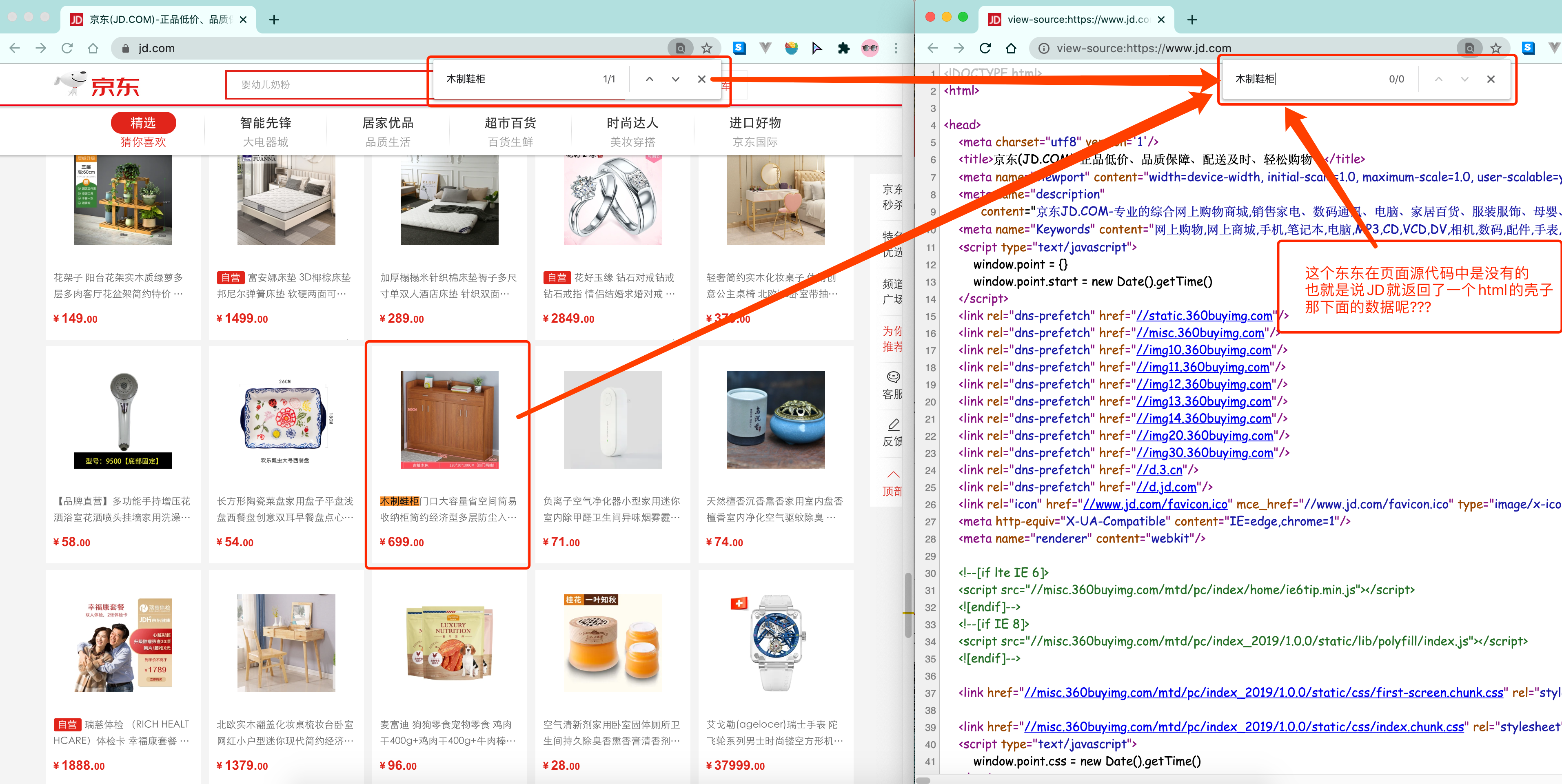
那数据是何时加载进来的呢? 其实就是在我们进行页面向下滚动的时候, jd就在偷偷的加载数据了, 此时想要看到这个页面的加载全过程, 我们就需要借助浏览器的调试工具了(F12)
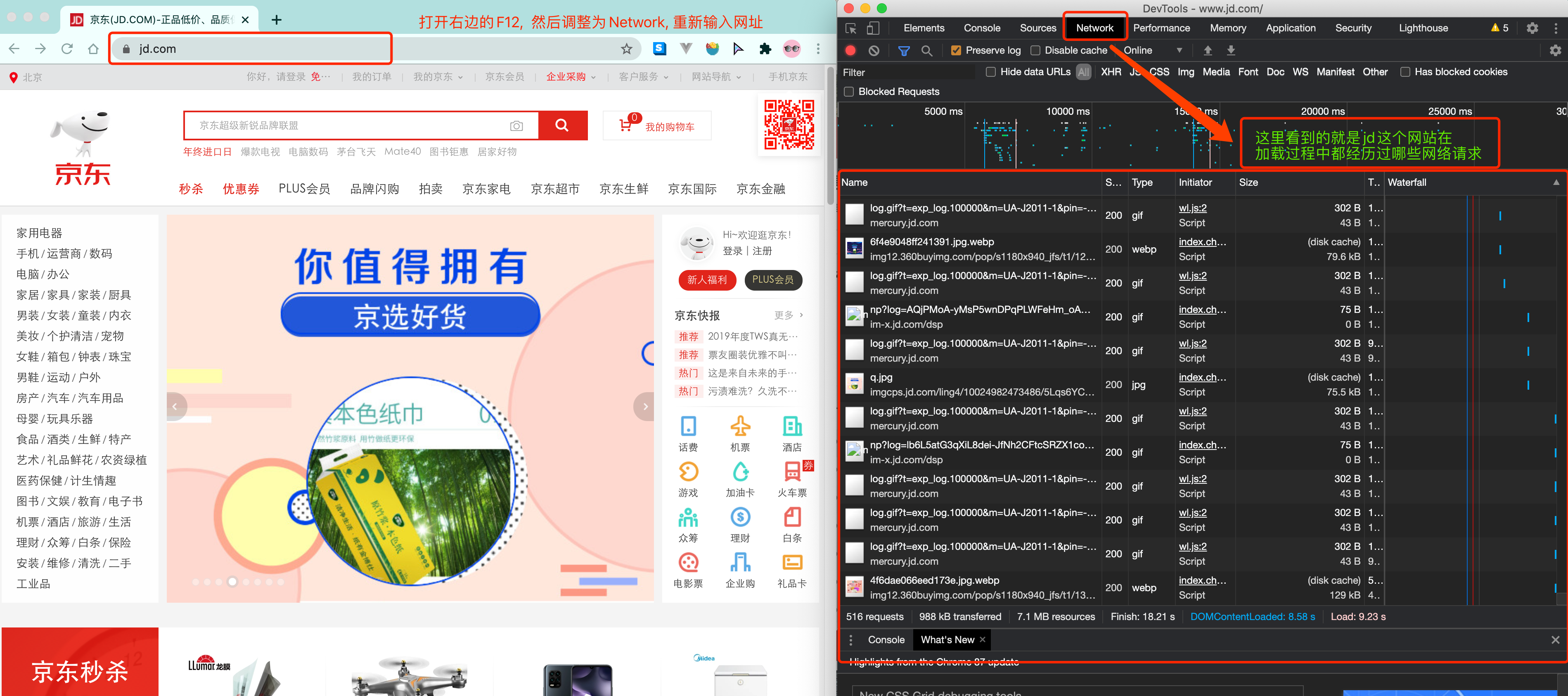
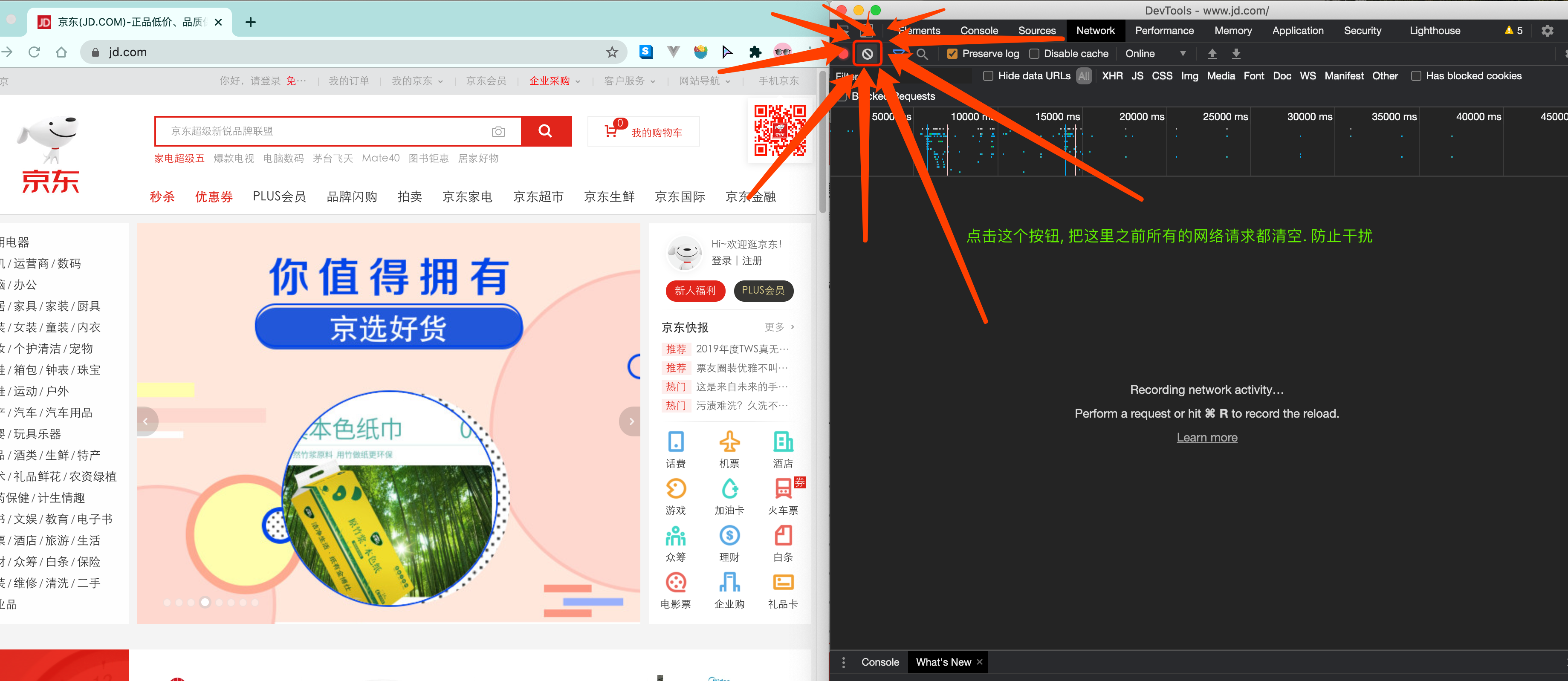
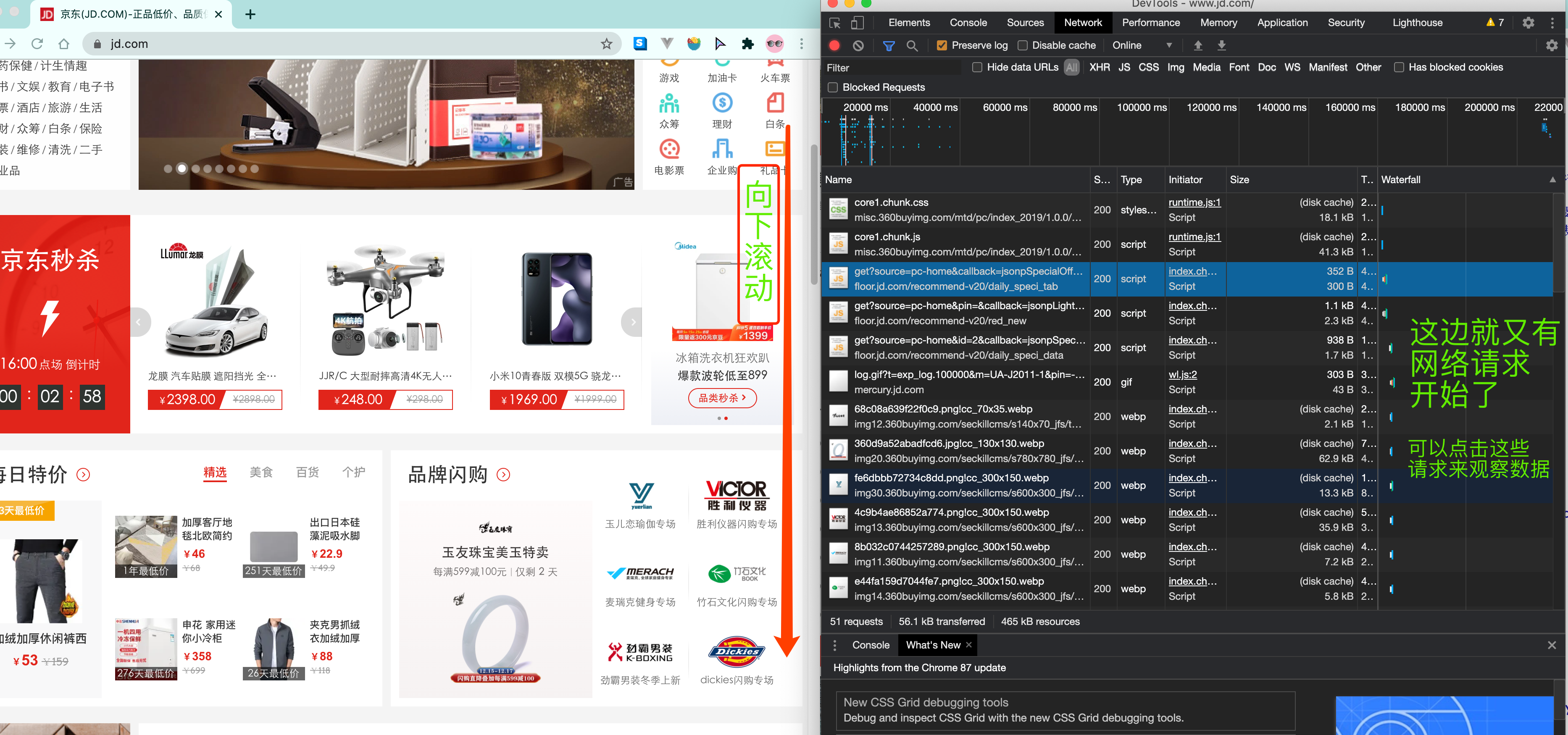
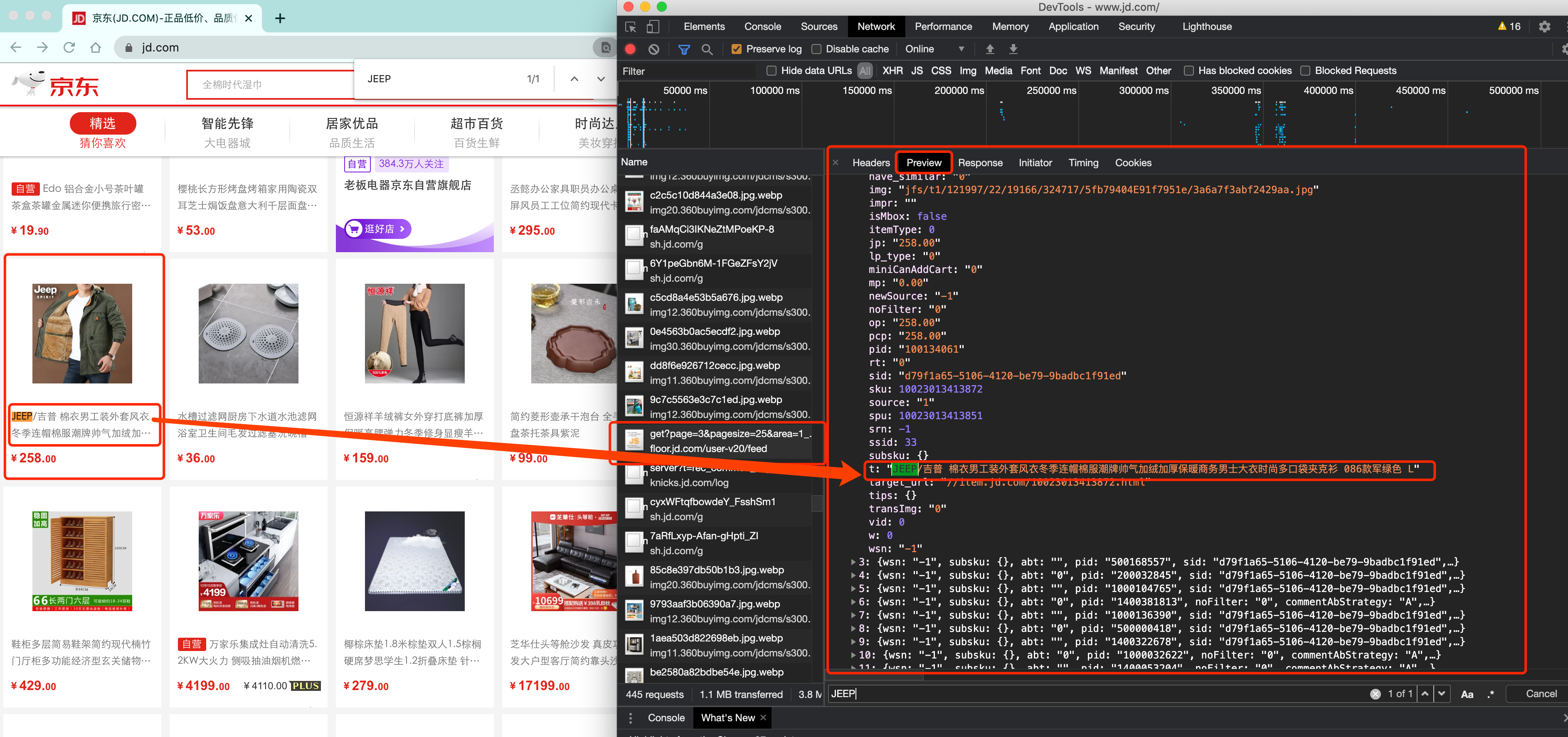
看到了吧, 页面上看到的内容其实是后加载进来的.
OK, 在这里我不是要跟各位讲jd有多牛B, 也不是说这两种方式有什么不同, 只是想告诉各位, 有些时候, 我们的数据不一定都是直接来自于页面源代码. 如果你在页面源代码中找不到你要的数据时, 那很可能数据是存放在另一个请求里.
1
2
1.你要的东西在页面源代码. 直接拿`源代码`提取数据即可
2.你要的东西,不在页面源代码, 需要想办法找到真正的加载数据的那个请求. 然后提取数据
二、浏览器工具的使用
Chrome是一款非常优秀的浏览器. 不仅仅体现在用户使用上. 对于我们开发人员而言也是非常非常好用的.
对于一名爬虫工程师而言. 浏览器是最能直观的看到网页情况以及网页加载内容的地方. 我们可以按下F12来查看一些普通用户很少能使用到的工具.
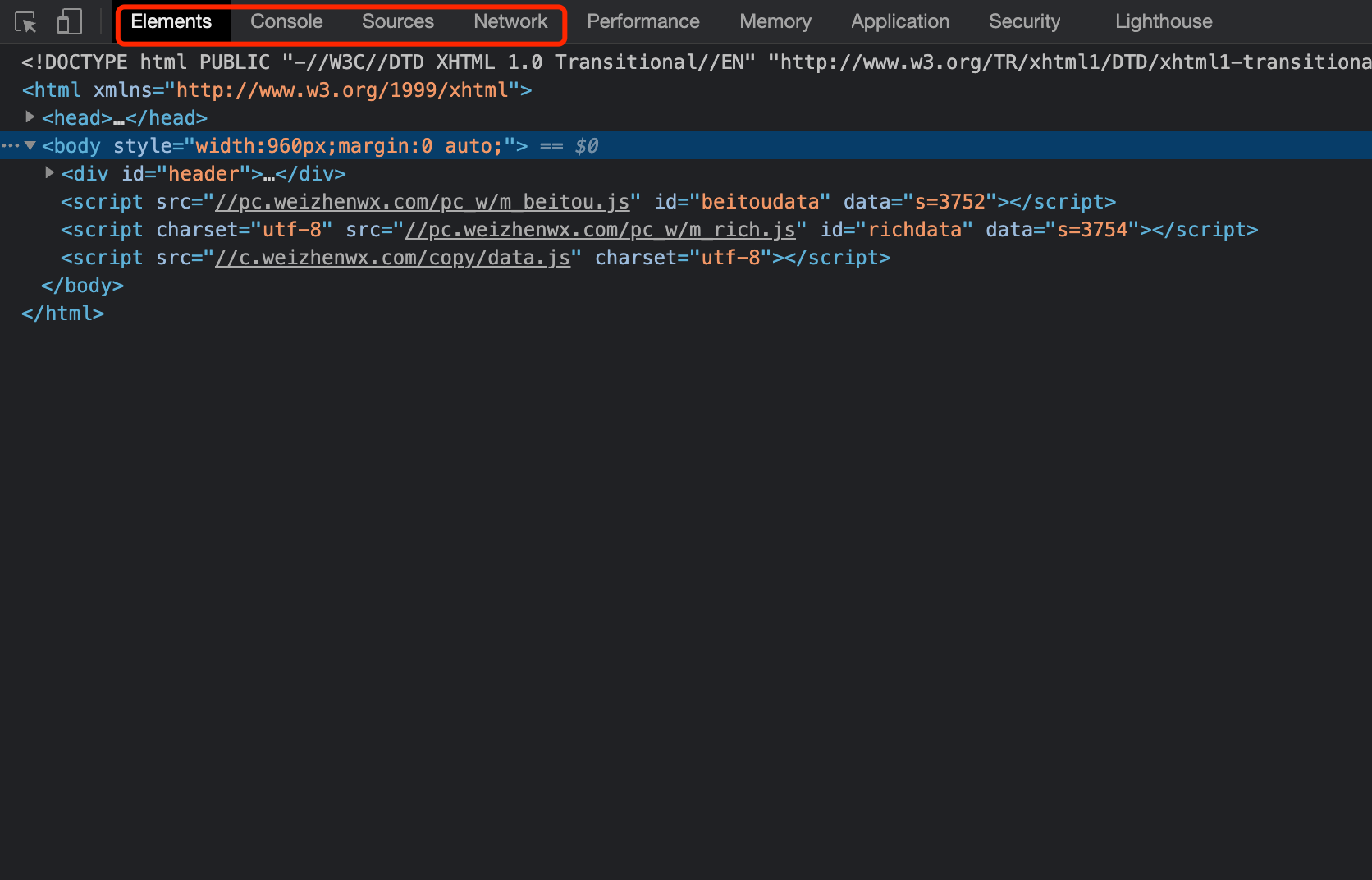
其中, 最重要的Elements, Console, Sources, Network.
Elements是我们实时的网页内容情况, 注意, 很多兄弟尤其到了后期. 非常容易混淆Elements以及页面源代码之间的关系.
注意,
- 页面源代码是执行js脚本以及用户操作之前的服务器返回给我们最原始的内容
- Elements中看到的内容是js脚本以及用户操作之后的当时的页面显示效果.
你可以理解为, 一个是老师批改之前的卷子, 一个是老师批改之后的卷子. 虽然都是卷子. 但是内容是不一样的. 而我们目前能够拿到的都是页面源代码. 也就是老师批改之前的样子. 这一点要格外注意.
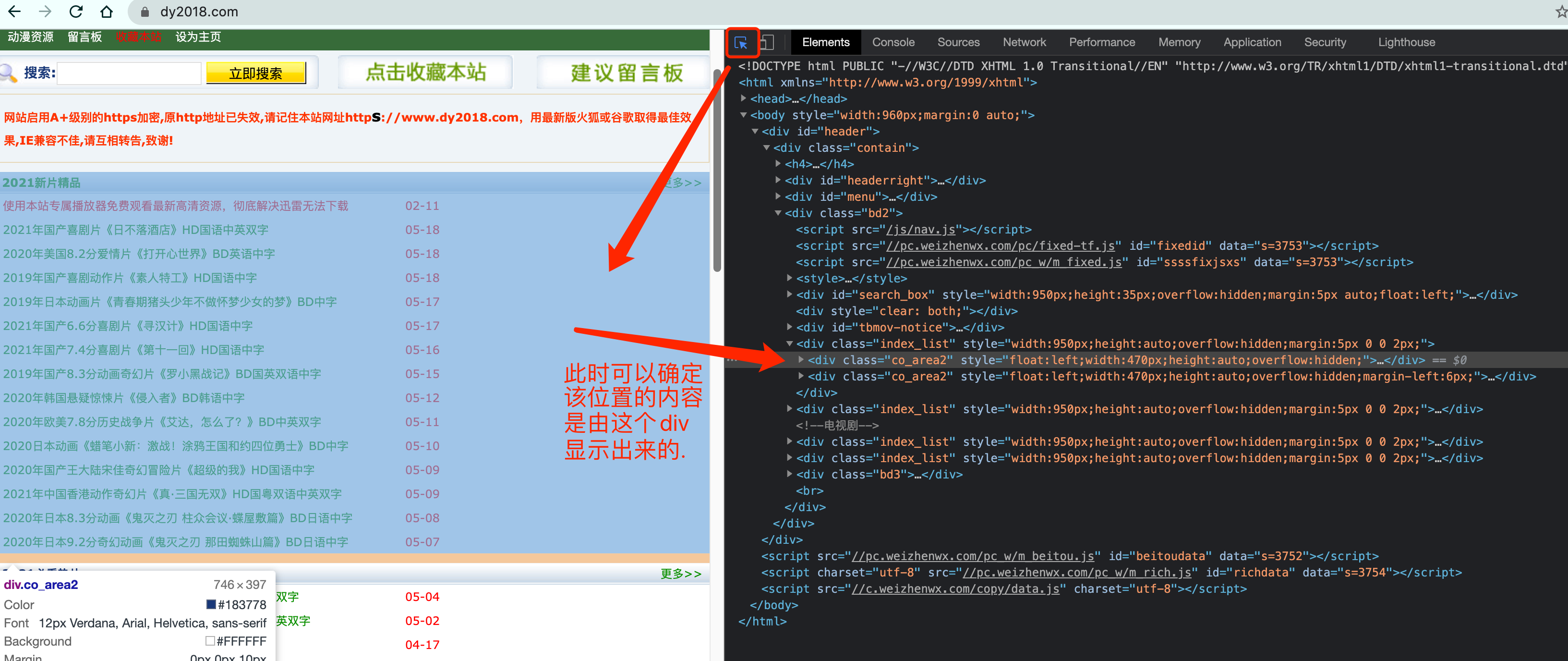
在Elements中我们可以使用左上角的小箭头.可以直观的看到浏览器中每一块位置对应的当前html状况. 还是很贴心的.
第二个窗口, Console是用来查看程序员留下的一些打印内容, 以及日志内容的. 我们可以在这里输入一些js代码自动执行.
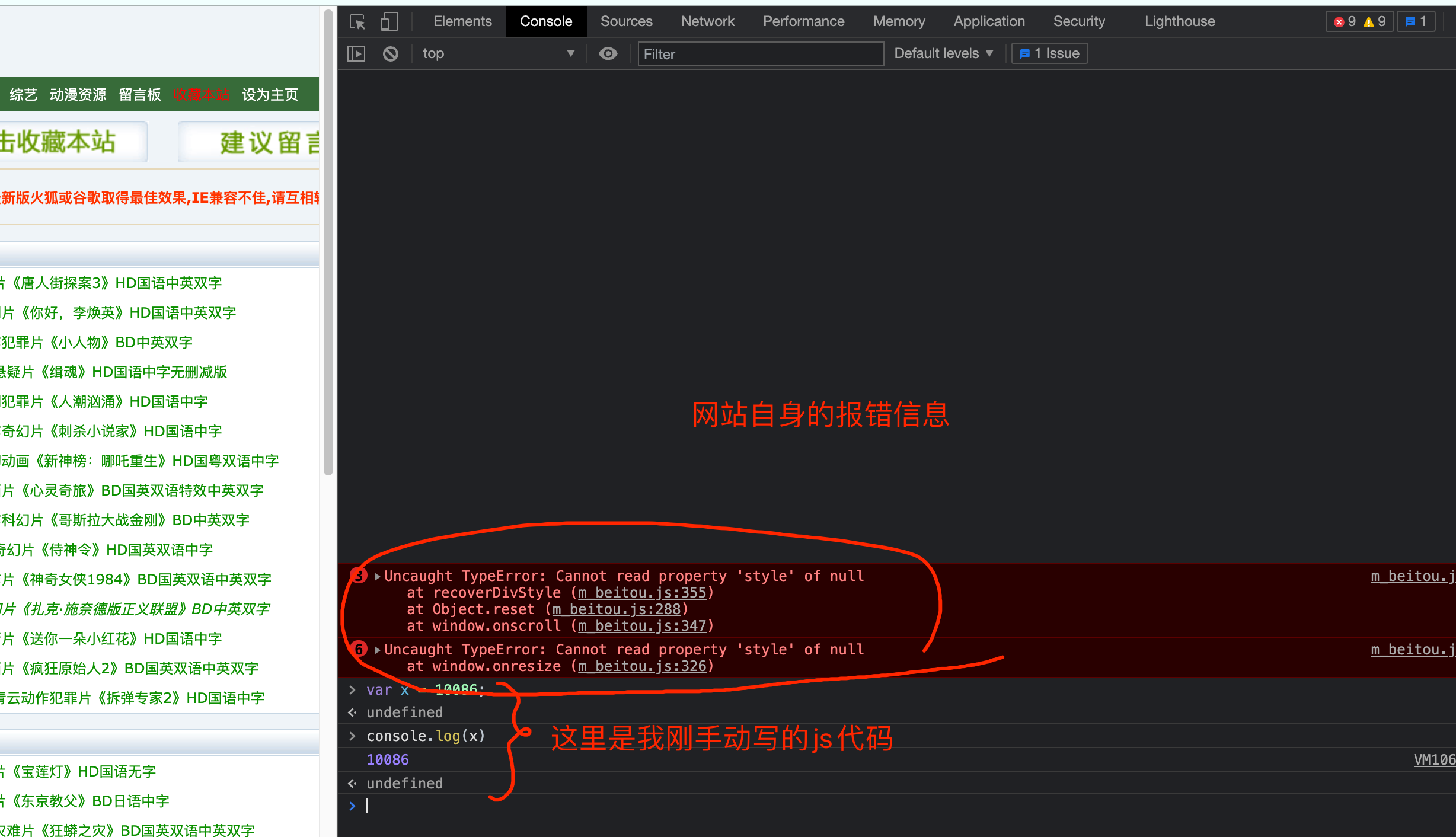
等咱们后面讲解js逆向的时候会用到这里.
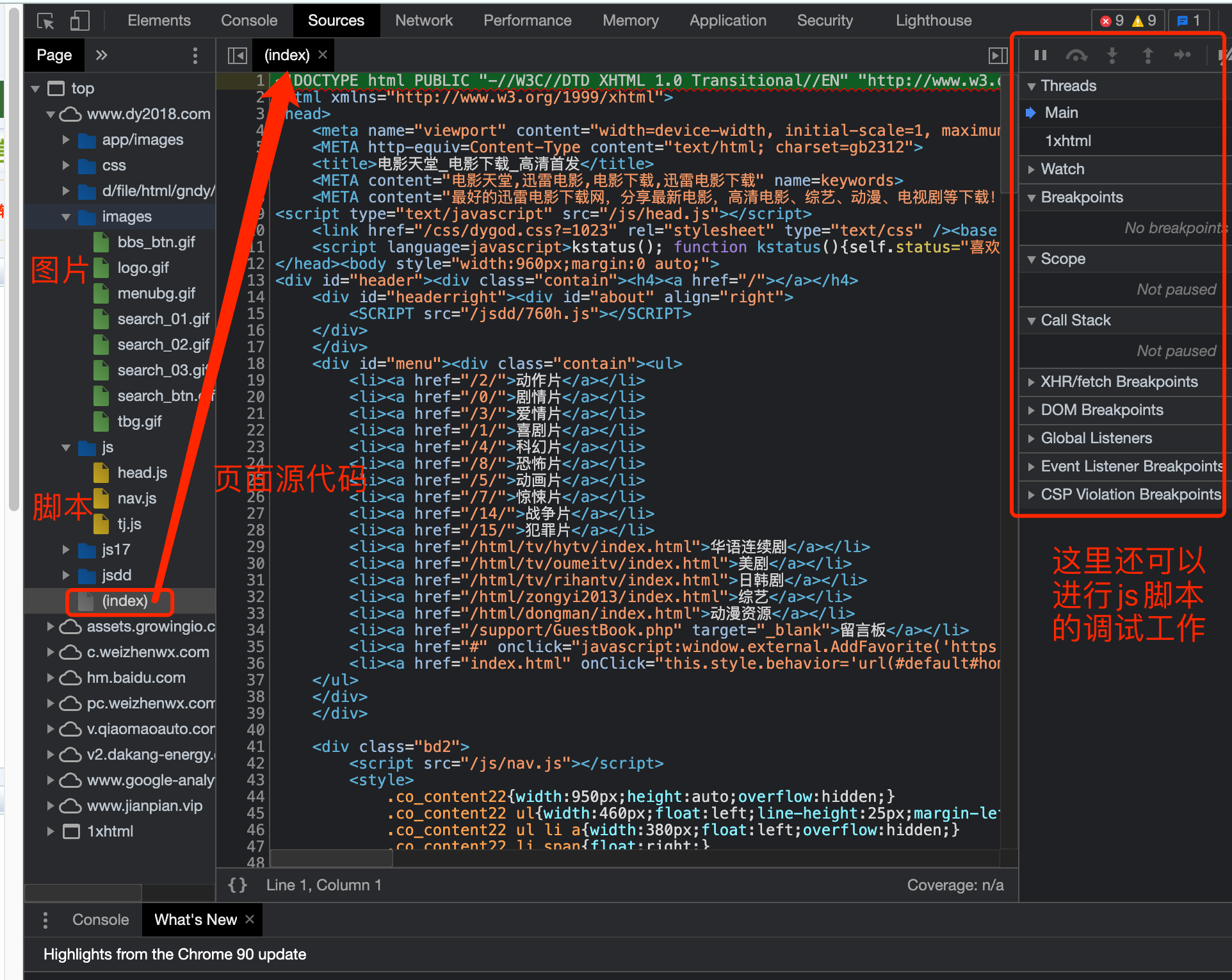
第三个窗口, Source, 这里能看到该网页打开时加载的所有内容. 包括页面源代码. 脚本. 样式, 图片等等全部内容.
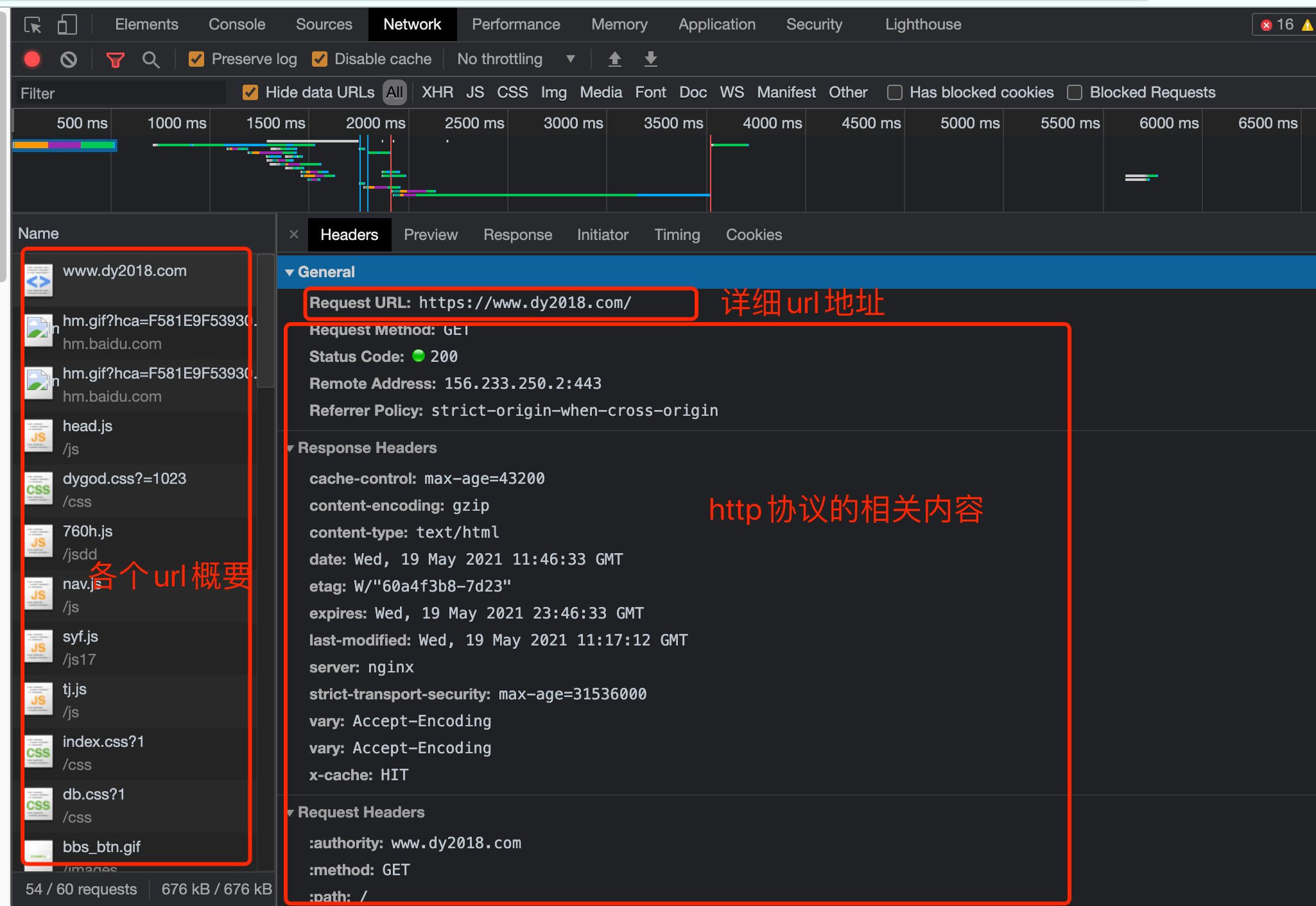
第四个窗口, Network, 我们一般习惯称呼它为抓包工具. 在这里, 我们能看到当前网页加载的所有网路网络请求, 以及请求的详细内容. 这一点对我们爬虫来说至关重要.
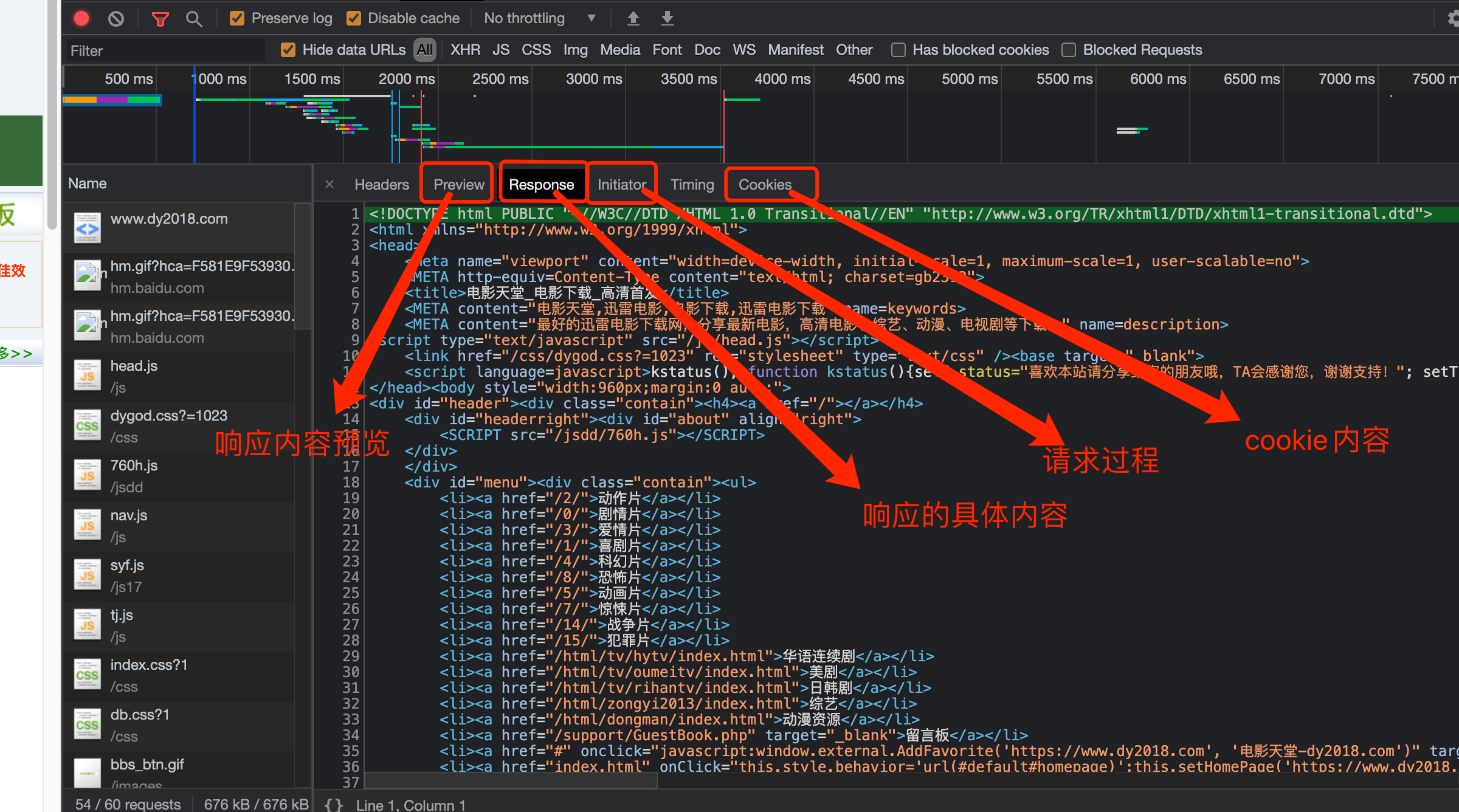
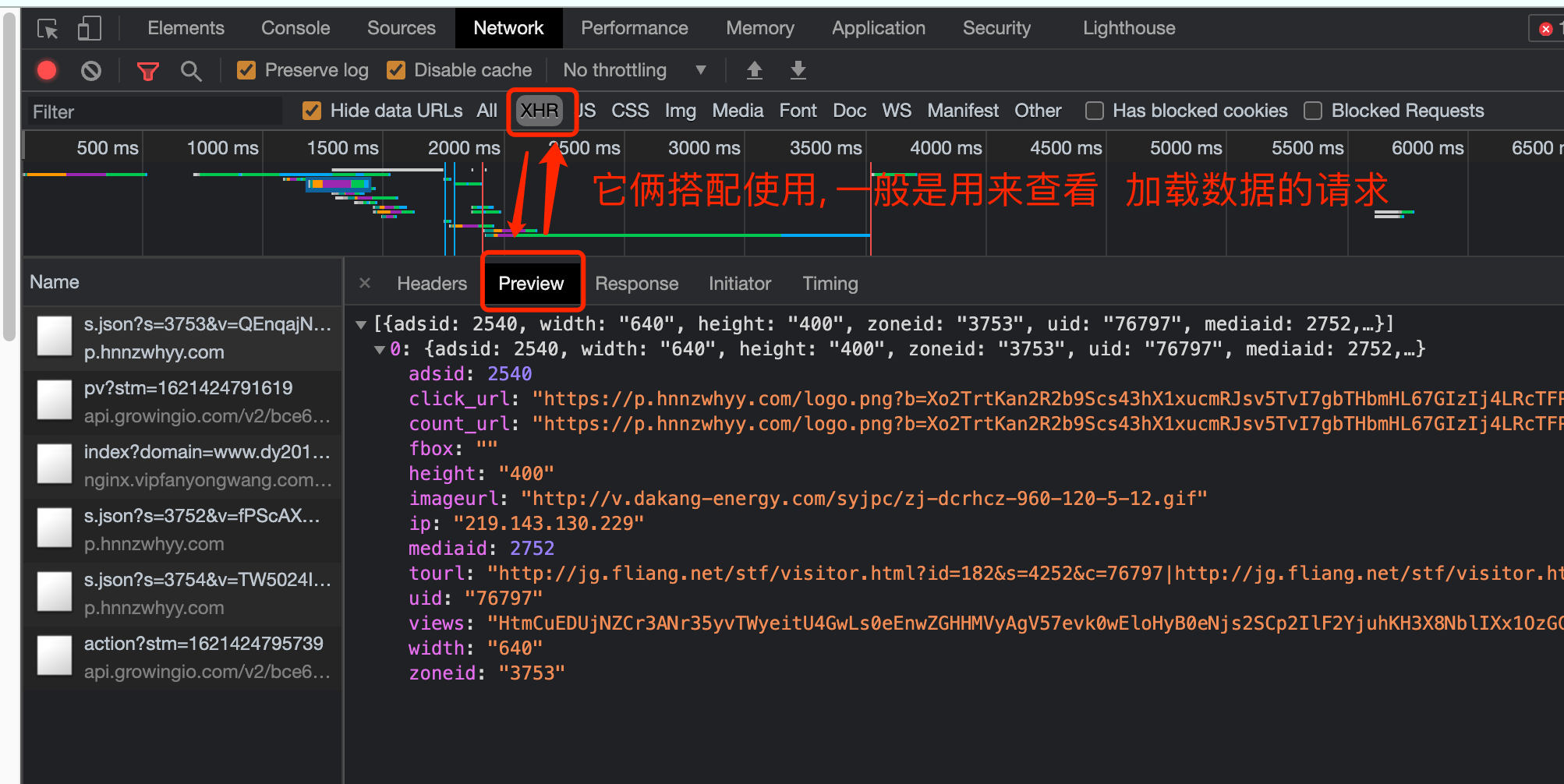
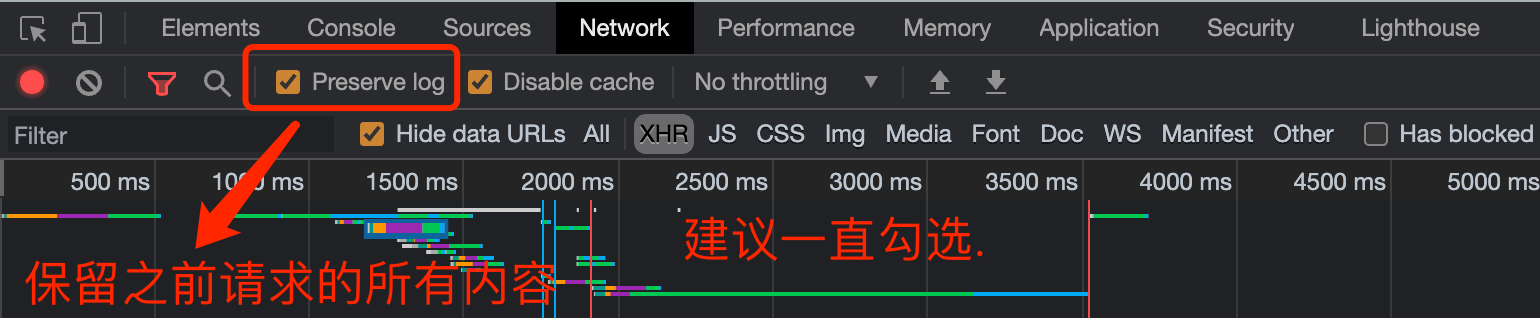
其他更加具体的内容. 随着咱们学习的展开. 会逐一进行讲解.
三、反爬虫的一般手段
爬虫项目最复杂的不是页面信息的提取,反而是爬虫与反爬虫、反反爬虫的博弈过程
User-Agent
浏览器的标志信息,会通过请求头传递给服务器,用以说明访问数据的浏览器信息
反爬虫:先检查是否有UA,或者UA是否合法
代理IP
验证码访问
动态加载网页
数据加密
…
四、常见HTTP状态码
200:这个是最常见的http状态码,表示服务器已经成功接受请求,并将返回客户端所请
- 100-199 用于指定客户端应相应的某些动作。
- 200-299 用于表示请求成功。
- 300-399 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息。
- 400-499 用于指出客户端的错误。
- 404:请求失败,客户端请求的资源没有找到或者是不存在
- 500-599 服务器遇到未知的错误,导致无法完成客户端当前的请求。