03 MySQL
第一章 连接池
1 连接池概述
为什么要使用连接池
目的:为了解决建立数据库连接耗费资源和时间很多的问题,提高性能。
Connection对象在JDBC使用的时候就会去创建一个对象,使用结束以后就会将这个对象给销毁了(close).每次创建和销毁对象都是耗时操作.需要使用连接池对其进行优化.
程序初始化的时候,初始化多个连接,将多个连接放入到池(集合)中.每次获取的时候,都可以直接从连接池中进行获取.使用结束以后,将连接归还到池中.
生活里面的连接池例子
老方式:
下了地铁需要骑车, 跑去生产一个, 然后骑完之后,直接把车销毁了.
连接池方式 摩拜单车:
骑之前, 有一个公司生产了很多的自行车, 下了地铁需要骑车, 直接扫码使用就好了, 然后骑完之后, 还回去

连接池原理【重点】
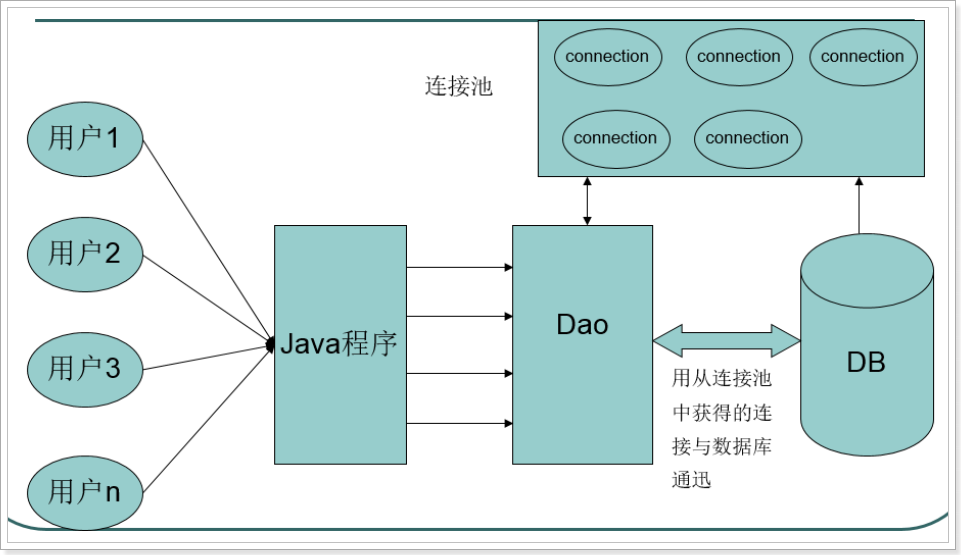
- 程序一开始就创建一定数量的连接,放在一个容器中,这个容器称为连接池(相当于碗柜/容器)。
- 使用的时候直接从连接池中取一个已经创建好的连接对象。
- 关闭的时候不是真正关闭连接,而是将连接对象再次放回到连接池中。
2 编写标准的数据源(规范)
Java为数据库连接池提供了公共的接口:javax.sql.DataSource,各个厂商需要让自己的连接池实现这个接口。这样应用程序可以方便的切换不同厂商的连接池!
常见的第三方连接池如下:
- C3P0是一个开源的JDBC连接池,它实现了数据源和JNDI绑定,支持JDBC3规范和JDBC2的标准扩展。C3P0是异步操作的,所以一些操作时间过长的JDBC通过其它的辅助线程完成。目前使用它的开源项目有Hibernate,Spring等。C3P0有自动回收空闲连接功能
- 阿里巴巴-德鲁伊druid连接池:Druid是阿里巴巴开源平台上的一个项目,整个项目由数据库连接池、插件框架和SQL解析器组成。该项目主要是为了扩展JDBC的一些限制,可以让程序员实现一些特殊的需求。
- DBCP(DataBase Connection Pool)数据库连接池,是Apache上的一个Java连接池项目,也是Tomcat使用的连接池组件。dbcp没有自动回收空闲连接的功能。
3 C3P0连接池
C3P0开源免费的连接池!目前使用它的开源项目有:Spring、Hibernate等。使用C3P0连接池需要导入jar包,c3p0使用时还需要添加配置文件“c3p0-config.xml”
C3P0连接池工具类编写
使用步骤
- 导入c3p0-0.9.1.2.jar
- 拷贝配置文件到src目录
- 创建连接池(配置文件自动读取的)
- 编写配置文件 c3p0-config.xml
1
2
3
4
5
6
7
8
9
10
11
12
<c3p0-config>
<!-- 使用默认的配置读取连接池对象 -->
<default-config>
<!-- 连接参数 -->
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/day19</property>
<property name="user">root</property>
<property name="password">root</property>
<!-- 连接池参数 -->
<property name="initialPoolSize">5</property>
</default-config>
</c3p0-config>
c3p0连接池常用的配置参数:
| 参数 | 说明 |
|---|---|
| initialPoolSize | 初始连接数 |
| maxPoolSize | 最大连接数 |
| checkoutTimeout | 最大等待时间 |
| maxIdleTime | 最大空闲回收时间 |
初始连接数:刚创建好连接池的时候准备的连接数量 最大连接数:连接池中最多可以放多少个连接 最大等待时间:连接池中没有连接时最长等待时间 最大空闲回收时间:连接池中的空闲连接多久没有使用就会回收
编写Java代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
/**
* C3P0连接池的工具类
*
*/
public class C3P0Utils {
//1. 创建一个C3P0的连接池对象(会自动读取src目录下的c3p0-config.xml,所以不需要我们解析配置文件)
public static DataSource ds = new ComboPooledDataSource();
//2. 提供 从连接池中 获取连接对象的方法
public static Connection getConnection() throws SQLException {
Connection conn = ds.getConnection();
return conn;
}
//3. 提供 获得数据源(连接池对象)的方法
public static DataSource getDataSource(){
return ds;
}
}
4 Druid 连接池
Druid是阿里巴巴开发的号称为监控而生的数据库连接池,Druid是国内目前最好的数据库连接池。在功能、性能、扩展性方面,都超过其他数据库连接池。Druid已经在阿里巴巴部署了超过600个应用,经过一年多生产环境大规模部署的严苛考验。如:一年一度的双十一活动,每年春运的抢火车票。
Druid的下载地址:https://github.com/alibaba/druid
DRUID连接池使用的jar包:druid-1.1.16.jar
Druid连接池工具类编写
步骤:
- 导入DRUID jar 包
- 拷贝配置文件到src目录
- 根据配置文件 创建连接池对象
- 从连接池对象获得连接
实现:
创建druid.properties, 放在src目录下
1
2
3
4
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/day19
username=root
password=root
编写Java代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
/**
* 阿里巴巴的连接池 Druid 工具类
*/
public class DruidUtils {
/*
1. 加载 druid.properties 配置文件
2. 创建 Druid 连接池对象
3. 提供 获得 连接池对象的方法
4. 提供 从连接池中 获取连接对象Connection的 方法
*/
public static DataSource ds = null;
static {
try {
//1. 加载 druid.properties 配置文件
InputStream is = DruidUtils.class.getClassLoader().getResourceAsStream("druid.properties");
Properties prop = new Properties();
prop.load(is);
//2. 创建 Druid 连接池对象
ds = DruidDataSourceFactory.createDataSource(prop);
} catch (Exception e) {
e.printStackTrace();
}
}
/*
3. 提供 获得 连接池对象的方法
*/
public static DataSource getDataSource(){
return ds;
}
/*
4. 提供 从连接池中 获取连接对象Connection的 方法
*/
public static Connection getConnetion() throws SQLException {
Connection conn = ds.getConnection();
return conn;
}
}
第二章 DBUtils
如果只使用JDBC进行开发,我们会发现冗余代码过多,为了简化JDBC开发,本案例我们讲采用apache commons组件一个成员:DBUtils。
DBUtils就是JDBC的简化开发工具包。需要项目导入commons-dbutils-1.6.jar才能够正常使用DBUtils工具。
1 概述
DBUtils 是 Java 编程中的数据库操作实用工具,小巧简单实用。DBUtils 封装了对 JDBC 的操作,简化了 JDBC 操作,可以少写代码。
Dbutils 三个核心功能介绍
- QueryRunner 中提供对 SQL 语句操作的API。
- ResultSetHandler 接口,用于定义 select 操作后,怎样封装结果集。
- DbUtils 类,它就是一个工具类,定义了关闭资源与事务处理的方法
2 准备数据
- 创建表:
1
2
3
4
5
6
create table product(
pid int primary key,
pname varchar(20),
price double,
category_id varchar(32)
);
- 插入表记录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
INSERT INTO product(pid,pname,price,category_id) VALUES(1,'联想',5000,'c001');
INSERT INTO product(pid,pname,price,category_id) VALUES(2,'海尔',3000,'c001');
INSERT INTO product(pid,pname,price,category_id) VALUES(3,'雷神',5000,'c001');
INSERT INTO product(pid,pname,price,category_id) VALUES(4,'JACK JONES',800,'c002');
INSERT INTO product(pid,pname,price,category_id) VALUES(5,'真维斯',200,'c002');
INSERT INTO product(pid,pname,price,category_id) VALUES(6,'花花公子',440,'c002');
INSERT INTO product(pid,pname,price,category_id) VALUES(7,'劲霸',2000,'c002');
INSERT INTO product(pid,pname,price,category_id) VALUES(8,'香奈儿',800,'c003');
INSERT INTO product(pid,pname,price,category_id) VALUES(9,'相宜本草',200,'c003');
INSERT INTO product(pid,pname,price,category_id) VALUES(10,'面霸',5,'c003');
INSERT INTO product(pid,pname,price,category_id) VALUES(11,'好想你枣',56,'c004');
INSERT INTO product(pid,pname,price,category_id) VALUES(12,'香飘飘奶茶',1,'c005');
INSERT INTO product(pid,pname,price,category_id) VALUES(13,'果9',1,NULL);
3 QueryRunner 核心类介绍
提供数据源
- 构造方法
QueryRunner(DataSource)创建核心类,并提供数据源,内部自己维护Connection
- 普通方法
update(String sql , Object ... params)执行DML语句query(String sql , ResultSetHandler , Object ... params)执行DQL语句,并将查询结果封装到对象中。
提供连接
- 构造方法
QueryRunner()创建核心类,没有提供数据源,在进行具体操作时,需要手动提供Connection
- 普通方法
update(Connection conn , String sql , Object ... params)使用提供的Connection,完成DML语句query(Connection conn , String sql , ResultSetHandler , Object ... params)使用提供的Connection,执行DQL语句,并将查询结果封装到对象中。
4 QueryRunner实现添加、更新、删除操作
update(String sql, Object... params)用来完成表数据的增加、删除、更新操作
添加
1
2
3
4
5
6
7
8
9
10
11
// 插入数据
@Test
public void test1() throws SQLException {
//1. 获取 QueryRunnr对象, 这个用于执行 Sql语句
QueryRunner qr = new QueryRunner(DruidUtils.getDataSource());
//2. 执行sql代码
String sql = "insert into product values(?,?,?,?)";
int line = qr.update(sql, 14, "康师傅方便面", 5, "c005");
//3. 处理查询结果数据 ( 如果是插入, 更新, 删除操作 没有必要做 步骤3)
System.out.println("line = " + line);
}
更新
1
2
3
4
5
6
7
8
9
10
11
12
// 更新数据
@Test
public void test2() throws SQLException {
//1. 获取 QueryRunnr对象, 这个用于执行 Sql语句
QueryRunner qr = new QueryRunner(C3P0Utils.getDataSource());
//2. 执行sql代码
String sql = "update product set pname=? , price=? where pid=?";
int line = qr.update(sql, "统一方便面", 4.5, 14);
//3. 处理查询结果数据 ( 如果是插入, 更新, 删除操作 没有必要做 步骤3)
System.out.println("line = " + line);
}
删除
1
2
3
4
5
6
7
8
// 删除数据
@Test
public void test3() throws SQLException {
QueryRunner qr = new QueryRunner(DruidUtils.getDataSource());
String sql = "delete from product where pid = ?";
int line = qr.update(sql, 14);
System.out.println("line = " + line);
}
5 QueryRunner实现查询操作
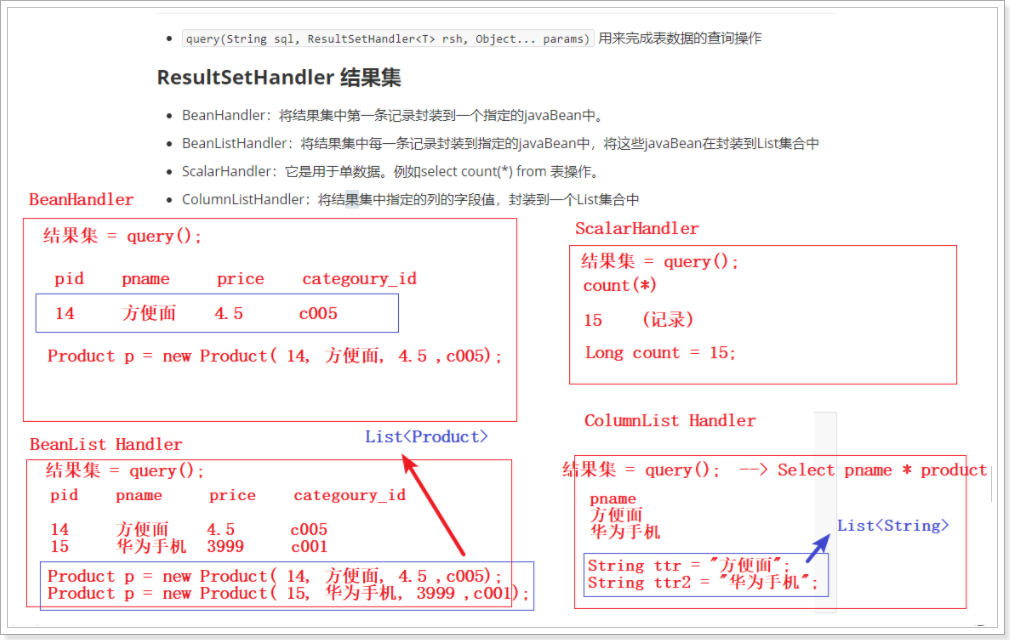
query(String sql, ResultSetHandler<T> rsh, Object... params)用来完成表数据的查询操作
ResultSetHandler 结果集
- BeanHandler:将结果集中第一条记录封装到一个指定的javaBean中。
- BeanListHandler:将结果集中每一条记录封装到指定的javaBean中,将这些javaBean在封装到List集合中
- ScalarHandler:它是用于单数据。例如select count(*) from 表操作。
- ColumnListHandler:将结果集中指定的列的字段值,封装到一个List集合中
JavaBean
JavaBean就是一个类,在开发中常用语封装数据。具有如下特性
- 需要实现接口:java.io.Serializable ,通常实现接口这步骤省略了,不会影响程序。
- 提供私有字段:private 类型 字段名;
- 提供getter/setter方法:
- 提供无参构造
1
2
3
4
5
6
7
8
9
public class Product {
private int pid;
private String pname;
private Double price;
private String category_id;
//省略 getter和setter方法
}
BeanHandler
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
/*
* 查询数据表结果集处理其中一种方式:
* BeanHandler处理方式
* 将数据表的结果集第一行数据,封装成JavaBean类的对象
* 构造方法:
* BeanHandler(Class<T> type)
* 传递一个Class类型对象,将结果封装到哪个类的对象呢
* ZhangWu类的Class对象
*/
@Test
public void demo01() throws SQLException{
// 通过id查询详情,将查询结果封装到JavaBean product
//1核心类
QueryRunner queryRunner = new QueryRunner(C3P0Utils.getDataSource());
//2 sql语句
String sql = "select * from product where pid = ?";
//3 实际参数
Object[] params = {6};
//4 查询并封装
Product product = queryRunner.query(sql, new BeanHandler<Product>(Product.class), params);
System.out.println(product);
}
BeanListHandler
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
/*
* 查询数据表结果集处理其中一种方式:
* BeanListHandler处理方式
* 将数据表的每一行数据,封装成JavaBean类对象
* 多行数据了,多个JavaBean对象,存储List集合
*/
@Test
public void demo02() throws SQLException{
//查询所有,将每一条记录封装到一个JavaBean,然后将JavaBean添加到List中,最后返回List,BeanListHandler
QueryRunner queryRunner = new QueryRunner(C3P0Utils.getDataSource());
String sql = "select * from product";
Object[] params = {};
List<Product> list = queryRunner.query(sql, new BeanListHandler<Product>(Product.class), params);
for(Product product : list){
System.out.println(product);
}
}
ScalarHander
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
/*
* 查询数据表结果集处理其中一种方式:
* ScalarHandler处理方式
* 处理单值查询结果,执行的select语句后,结果集只有1个
*/
@Test
public void demo03() throws SQLException{
// ScalarHandler : 用于处理聚合函数执行结果(一行一列)
// * 查询总记录数
QueryRunner queryRunner = new QueryRunner(C3P0Utils.getDataSource());
String sql = "select count(*) from product";
Long obj = queryRunner.query(sql, new ScalarHandler<Long>());
//System.out.println(obj.getClass());
System.out.println(obj);
}
ColumnListHandler
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
/*
* 查询数据表结果集处理其中一种方式:
* ColumnListHandler处理方式
* 将查询数据表结果集中的某一列数据,存储到List集合
* 哪个列不清楚,数据类型也不清楚, List<Object>
* ColumnListHandler构造方法
* 空参数: 获取就是数据表的第一列
* int参数: 传递列的顺序编号
* String参数: 传递列名
*
* 创建对象,可以加入泛型,但是加入的数据类型,要和查询的列类型一致
*/
@Test
public void demo04() throws SQLException{
// ColumnListHandler : 查询指定一列数据
QueryRunner queryRunner = new QueryRunner(C3P0Utils.getDataSource());
String sql = "select * from product";
List<String> list = queryRunner.query(sql, new ColumnListHandler<String>("pname"));
System.out.println(list);
}
6 小结
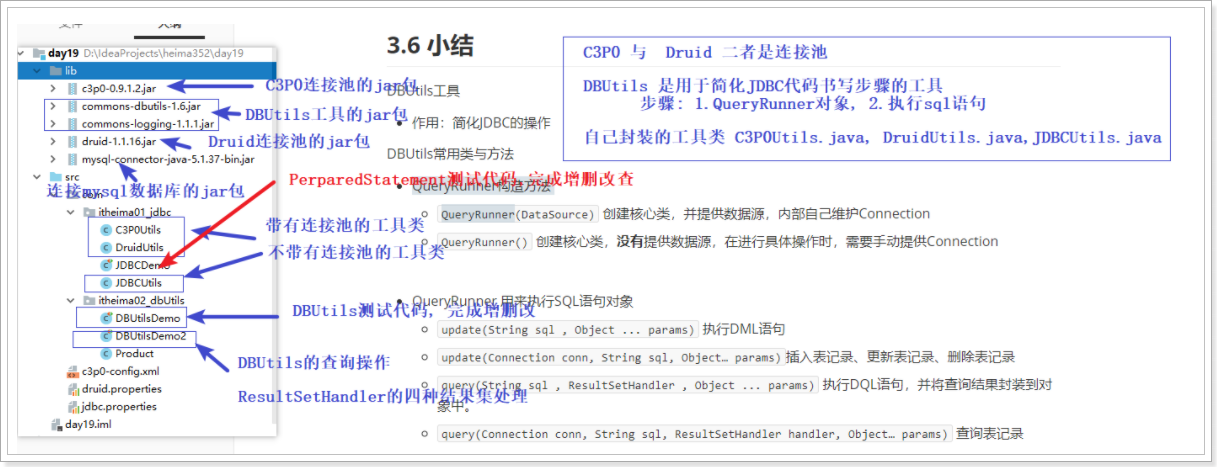
DBUtils工具
- 作用:简化JDBC的操作
DBUtils常用类与方法
QueryRunner构造方法
QueryRunner(DataSource)创建核心类,并提供数据源,内部自己维护ConnectionQueryRunner()创建核心类,没有提供数据源,在进行具体操作时,需要手动提供Connection
QueryRunner 用来执行SQL语句对象
update(String sql , Object ... params)执行DML语句update(Connection conn, String sql, Object… params)插入表记录、更新表记录、删除表记录query(String sql , ResultSetHandler , Object ... params)执行DQL语句,并将查询结果封装到对象中。query(Connection conn, String sql, ResultSetHandler handler, Object… params)查询表记录
ResultSetHandler 处理结果集的对象
- BeanHandler:将结果集中第一条记录封装到一个指定的javaBean中。
BeanHandler<Product>(Product.class) --> Proudct
- BeanListHandler:将结果集中每一条记录封装到指定的javaBean中,将这些javaBean在封装到List集合中
BeanListHandler<Product>(Product.class) --> List<Product>
- ScalarHandler:它是用于单数据。例如select count(*) from 表操作。
ScalarHandler<Long>() --> Long
- ColumnListHandler:将结果集中指定的列的字段值,封装到一个List集合中
ColumnListHandler<String>("pname") --> List<String>
- BeanHandler:将结果集中第一条记录封装到一个指定的javaBean中。
第三章 事务
1 事务
一组sql语句(insert、update、delete),全部成功整体才算成功,一个失败整体也算失败。
举例: 转账 a给b转账100元,a 和 b的账户中都有1000元, 转账完成后会是什么结果?
使用sql语句描述上述过程:
准备工作:
财务表 t_account , 里面有 姓名列 name 和 余额列 money。 a=1000, b=1000
正常情况下:
1
2
3
4
update t_account set money = money -100 where name='a';
update t_account set money = money +100 where name='b';
结果: a=900; b=1100
异常情况下:
1
2
3
4
5
6
7
8
update t_account set money = money -100 where name='a';
发生异常;
update t_account set money = money +100 where name='b';
结果: a=900; b=1000
思考: 这种结果合理吗?如果在你的身上发生这样的事 你可以容忍吗?
如果出现了异常,怎么才算是合理的结果呢?
是不是两个操作 要么全成功,要么全失败?
事务的出现 解决上面的问题。 特点:要么全成功,要么全失败。
事务是如何处理异常情况的呢?
1
2
3
4
5
6
7
8
9
开启事务 (针对一组sql) a=1000 b=1000
update t_account set money = money -100 where name='a'; -- a=900;
发生异常; 进行事务管理 -- 事务回滚 -- 撤销修改操作: -- a=1000;
update t_account set money = money +100 where name='b';
结果: a=1000 b=1000
事务是如何处理正常情况的呢?
1
2
3
4
5
6
7
8
9
10
11
开启事务
update t_account set money = money -100 where name='a'; a=900;
update t_account set money = money +100 where name='b'; b=1100
提交事务,使更改的内容生效。
结果:a=900 b=1100
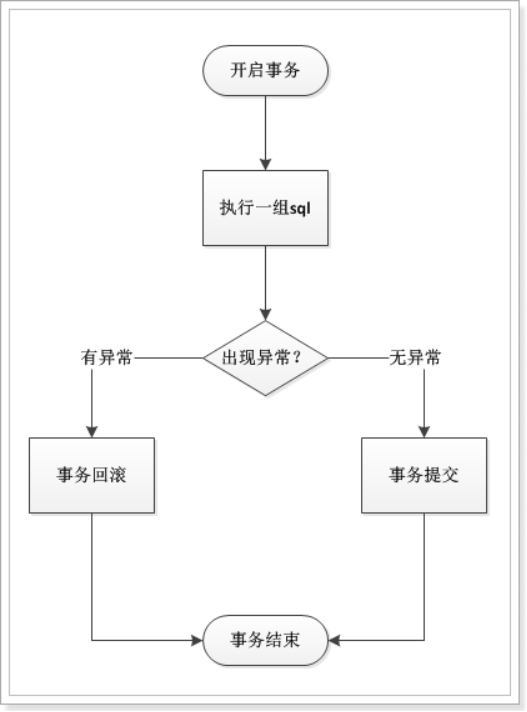 .
.
简单总结:
| 开启事务 | |
|---|---|
| 执行sql语句群 | |
| 出现异常 回滚事务(撤销) | 一切正常 事务提交(生效) |
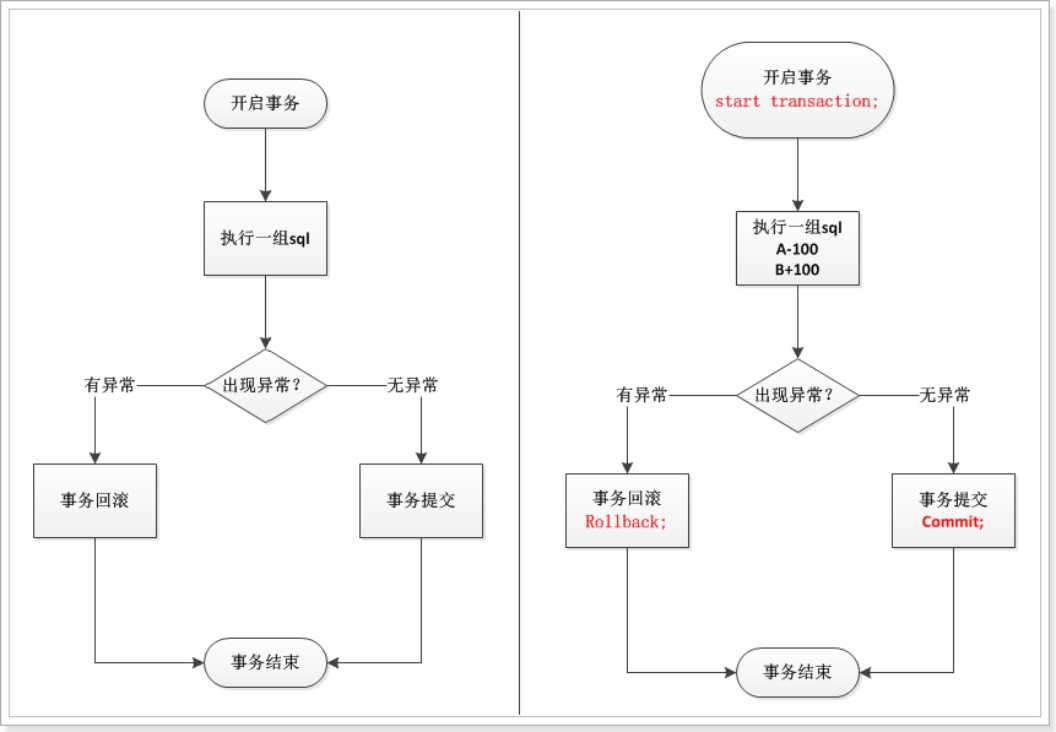
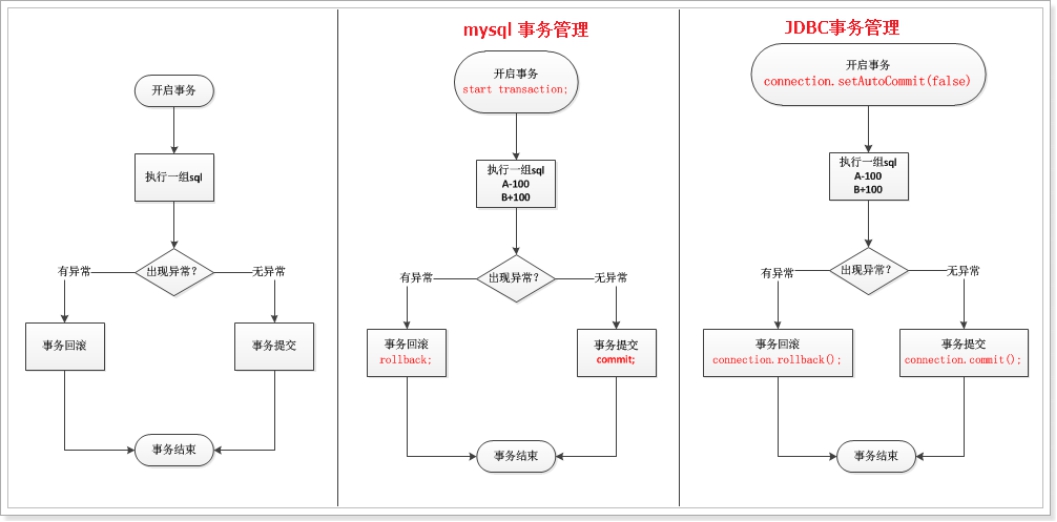
2. MySQL 中的事务管理
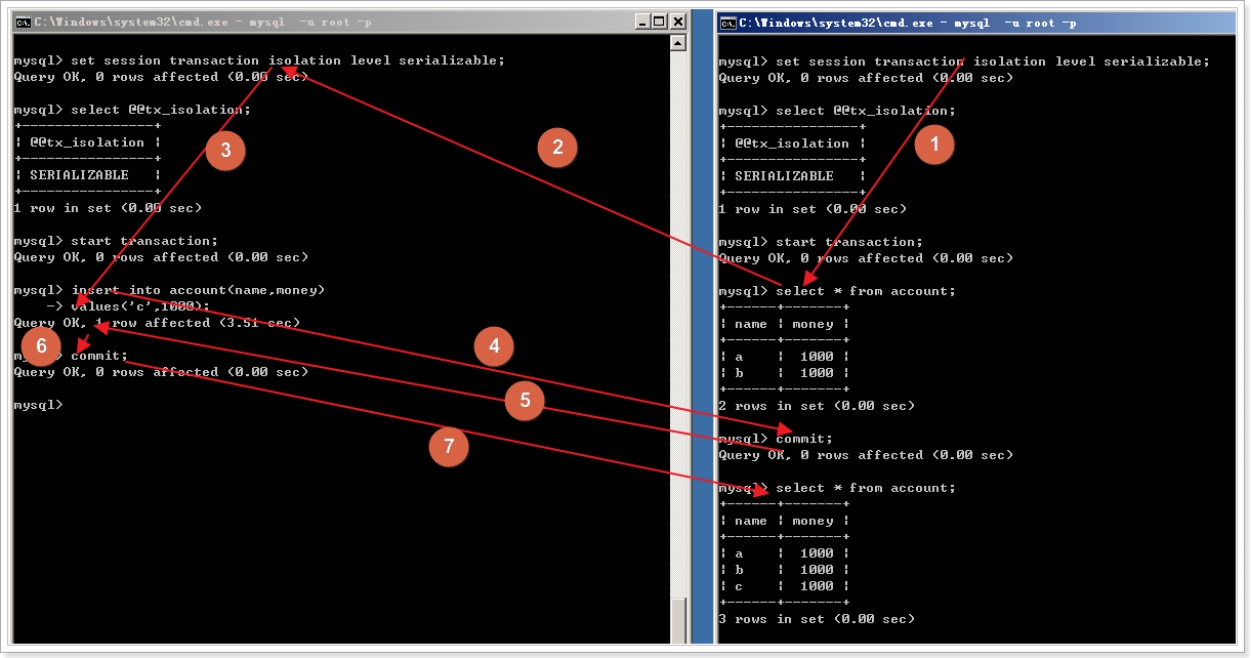
mysql 的事务 默认 自动打开,自动提交。 一条sql就是一个事务,所以不需要 事务开启、事务回滚、事务提交。
| 开启事务: start transaction; | |
|---|---|
| 执行sql语句群 | |
| 出现异常 事务回滚(撤销)事务结束 rollback; | 无异常 事务提交(生效) 事务结束 commit; |
1
2
3
4
5
start transaction; --- 开启事务。以后的sql都在一个事务中。更改的内容不会自动提交。
rollback; --- 回滚事务,都失败的情况。事务结束,全部失败,数据恢复到事务未开启之前的状态。
commit; --- 提交事务,都成功的情况。事务结束,全部成功。
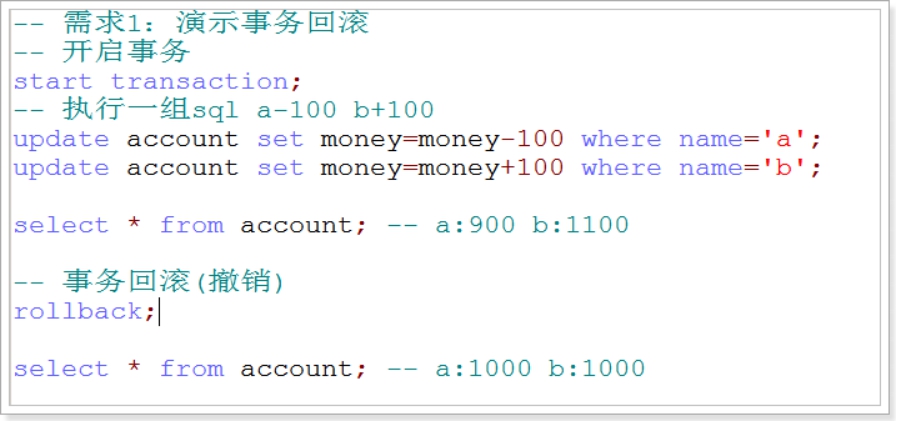
准备工作:
1
2
3
4
5
6
7
create table account(
name varchar(32),
money int
);
insert into account values('a', 1000);
insert into account values('b', 1000);
– 需求1:演示事务回滚
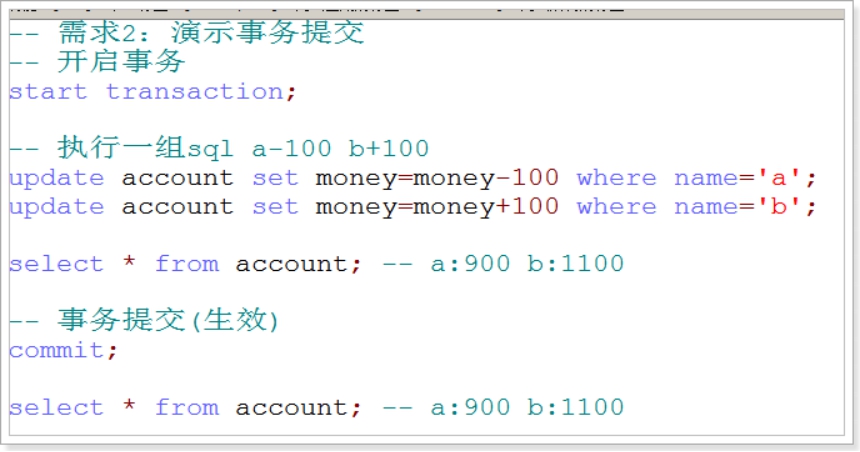
需求2:演示事务提交
3 事务的特性 ACID (理解)
事务是并发控制的基本单元。所谓事务一个sql语句操作序列,这些操作要么都执行,要么都不执行,他是一个不可分割的工作单元。
例如:银行转账工作,从一个帐号扣款并使另一个帐号增款,这个两个操作,要么都执行,要么都不执行。
数据库的事务必须具备ACID特性,ACID是指 Atomic(原子性)、Consistensy(一致性)、Isolation(隔离型)和Durability(持久性)的英文缩写。
1、原子性(Atomicity)
一个事务中所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中如果发生错误,会被回滚到事务开始前的状态,就像这个事务从来没有执行一样。
2、一致性(Consistency)
一个事务在执行之前和执行之后 数据库都必须处于一致性状态。
如果事务成功的完成,那么数据库的所有变化将生效。
如果事务执行出现错误,那么数据库的所有变化将会被回滚(撤销),返回到原始状态。
3、持久性:
指一个事务一旦被提交,它对数据库的改变将是永久性的,接下来即使数据库发生故障也不会对数据产生影响。
4、隔离性(Isolation)
多个用户并发的访问数据库时,一个用户的事务不能被其他用户的事务干扰,多个并发的事务之间要相互隔离。
多个事务事件是相互独立的,多个事务事件不能相互干扰。
4 隔离问题
如果不考虑事务的隔离型,由于事务的并发,将会出现以下问题:
1、脏读 – 最严重,杜绝发生
2、不可重复读
3、幻读(虚读)
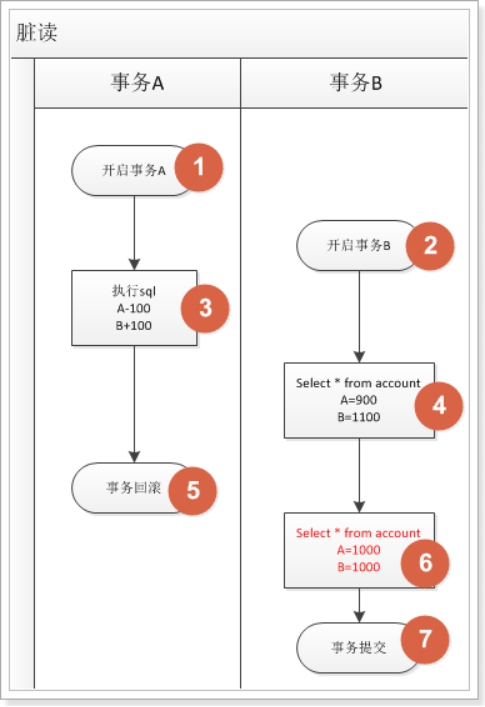
4.1 脏读:指一个事务读取了另外一个事务 未提交的数据
 .
.
假设A向B转账100元,对应的sql语句如下:
开启事务 update account set money=money-100 where name=’a’; update account set money=money+100 where nam=’b’;
两条sql语句执行完,b查询自己的账户多了100元。
b走后,a将事务进行回滚,这样B就损失了100元。
一个事务读取了另一个事务没有提交的数据,非常严重。应当尽量避免脏读。
4.2 不可重复读:在一个事务内多次读取表中的数据,多次读取的结果不同。
和脏读的区别: 不可重复读是读取的已提交数据
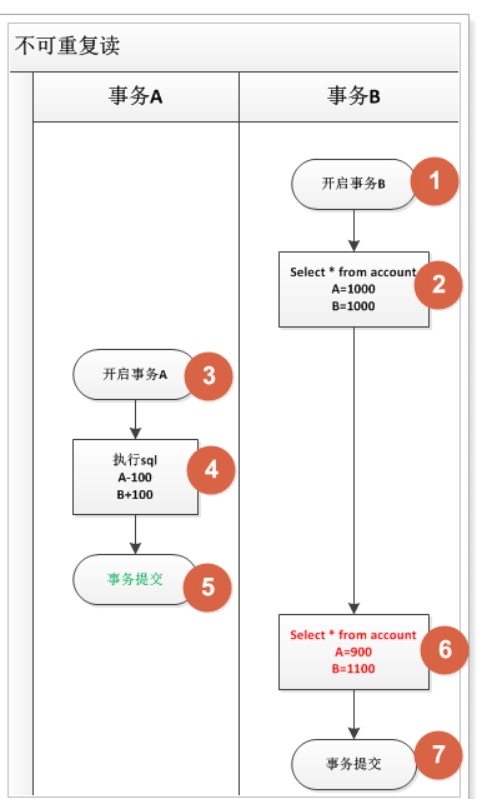
l 例如: 银行想查询A账户的余额,第一次查询的结果是200元,A向账户中又存了100元。此时,银行再次查询的结果变成了300元。两次查询的结果不一致,银行就会很困惑,以哪次为准。
l 和脏读不同的是:脏读读取的是前一事务未提交的数据,不可重复度 读取的是前一事务已提交的事务。
l 很多人认为这有啥好困惑的,肯定是以后面的结果为准了。我们需要考虑这样一种情况,查询A账户的余额,一个打印到控制台,一个输出到硬盘上,同一个事务中只是顺序不同,两次查询结果不一致,到底以哪个为准,你会不会困惑呢?
当前事务查询A账户的余额为100元,另外一个事务更新余额为300元并提交,导致当前事务使用同一查询结果却变成了300元。
4.3. 幻读(虚读)
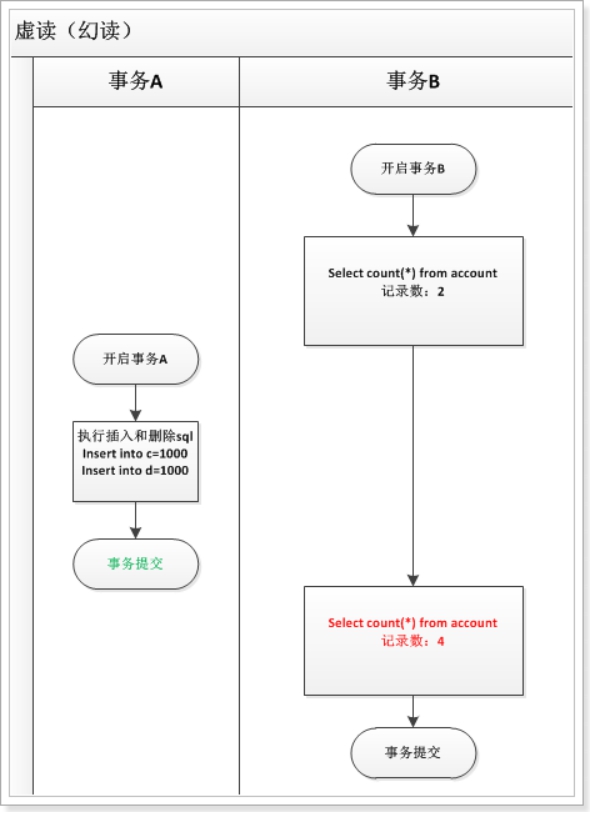
l 指在一个事务中 读取 另一个事务 插入或删除 数据记录,导致当前事务 读取数据前后不一致。
l 丙 存款100元但未提交,这时银行做报表 统计总额为500元,丙将事务提交,银行再统计就变成了 600元,两次统计结果不一致,银行便会不知所措。
一个事务 读取 另一个事务 已经提交的数据,强调的是 记录数 的变化,常有sql类型为 insert和 delete。
虚读和不可重复读的区别:
虚读 强调的是数据表 记录数 的变化,主要是 insert 和 delete 语句。
不可重复读 强调的是数据表 内容 的变化,主要是 update 语句。
5 数据库的隔离级别
数据库共定义了4种隔离级别(限制由高到低, 性能从低到高):
serializable(串行化):可避免 脏读、不可重复读、虚读情况的发生。
repeatable read(可重复读):可避免 脏读、不可重复读, 不可避免 虚读。mysql采用可重复读。
read committed(读已提交):可避免 脏读,不可避免 不可重复读、虚读。oracle采用读已提交。
read uncommitted(读未提交):不可避免 脏读、不可重复读、虚读。
查询当前数据库的隔离级别:
select @@tx_isolation;
设置事务的隔离级别:
set session transaction isolation level 事务隔离级别;
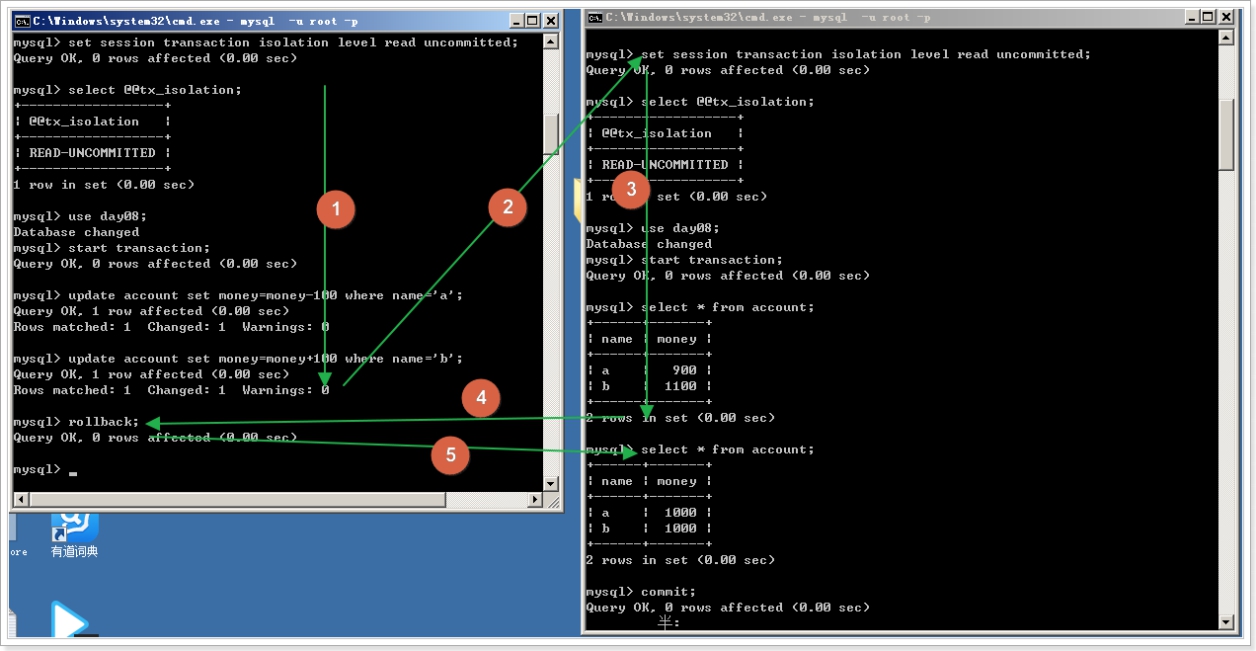
1、read uncommitted 读未提交
2.1 read committed 读已提交 避免脏读
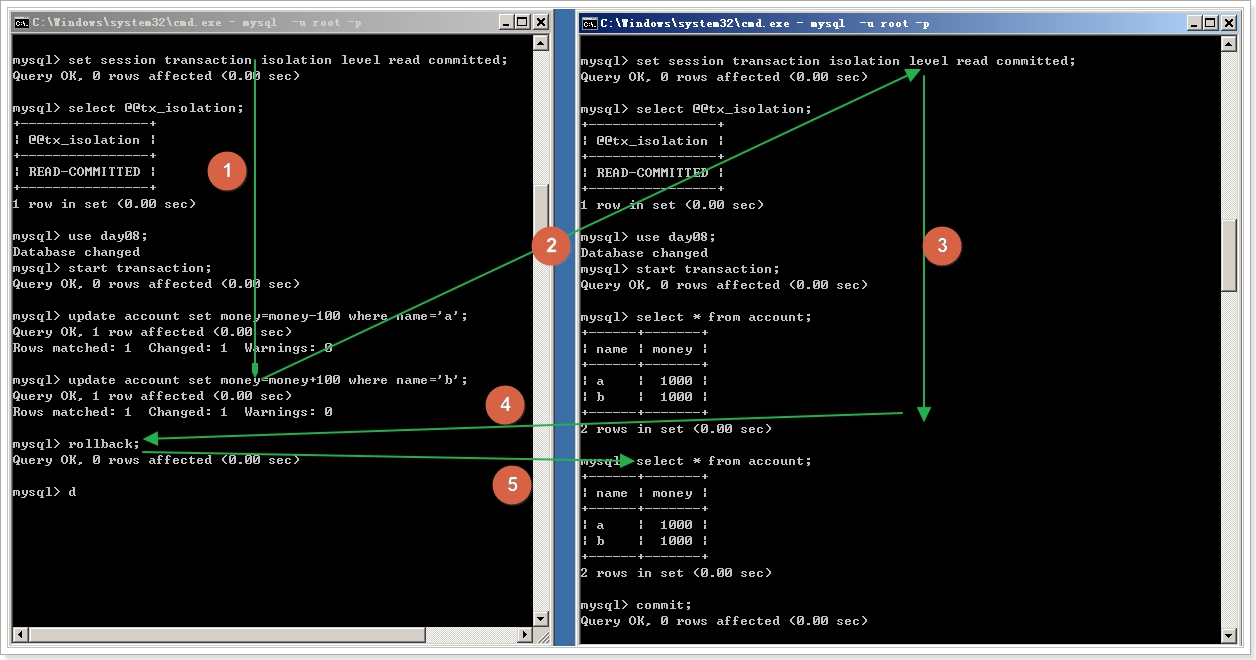
读已提交,没有解决 不可重复读, 回忆一下什么是不可重复读?
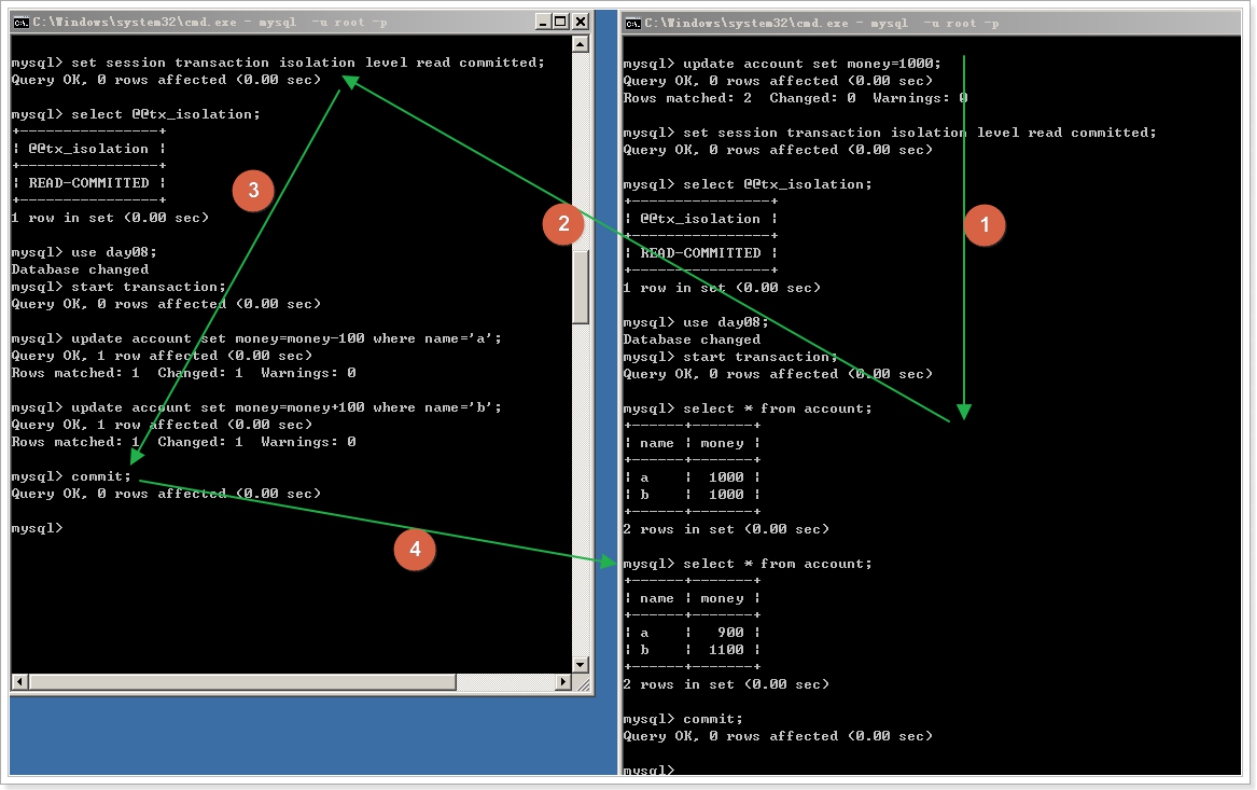
3、repeatable read 可重复读
可重复读的隔离级别可以解决 不可重复读的问题。
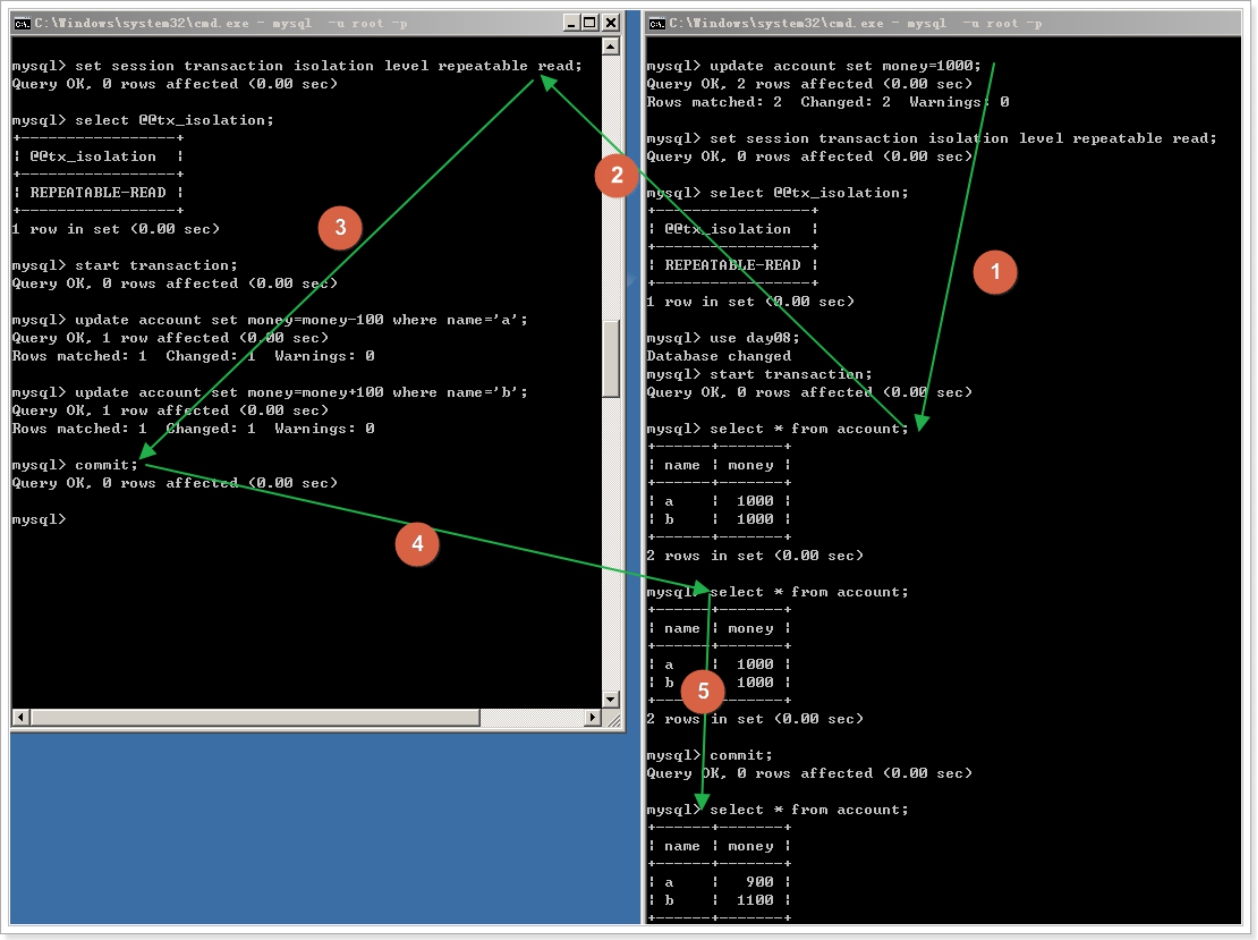
产生了虚读(幻读):
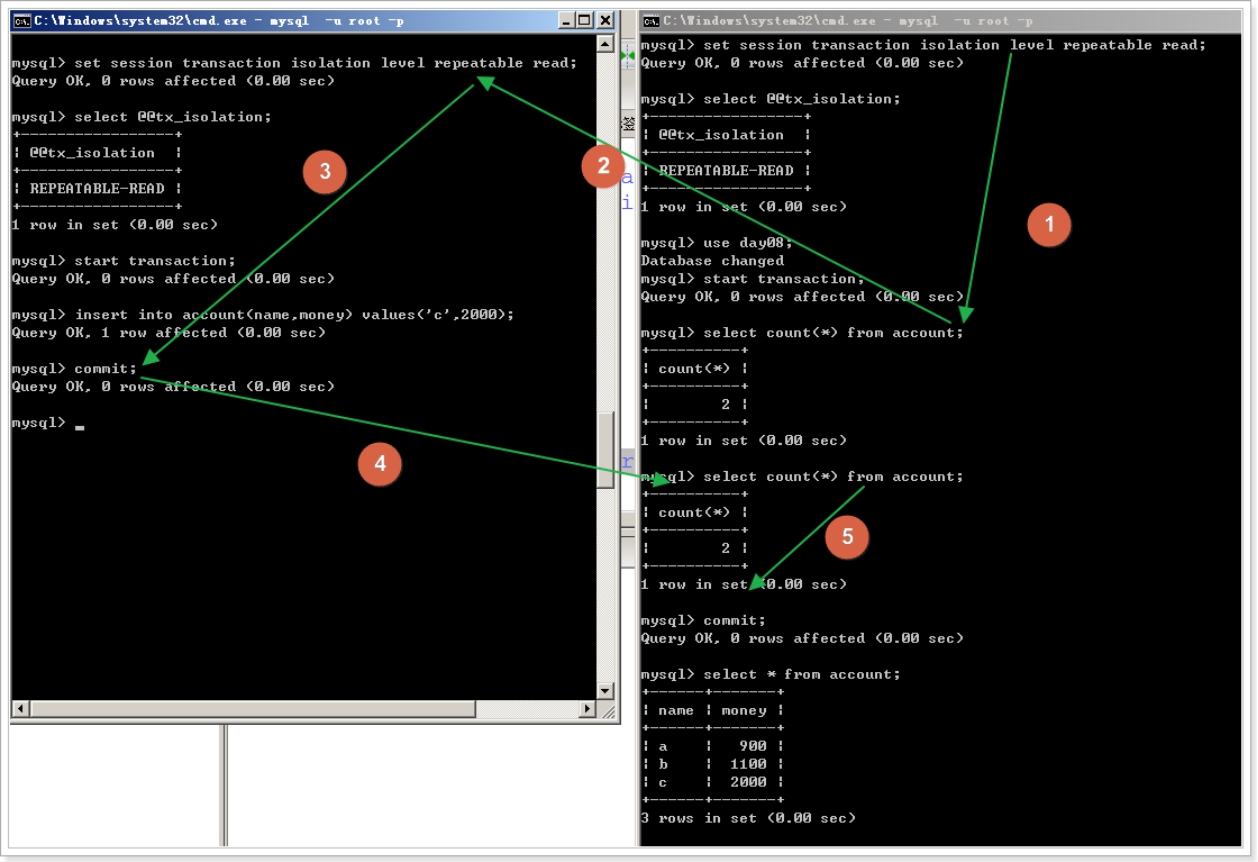
注意:mysql数据库本身,已经对虚读做了优化处理,所以展示不出虚读的发生。
4、serializable 串行化 可以避免所有的问题。数据库执行这个事务,其他事务必须等待当前事务执行完毕,才会执行。
思考题:为什么串行可以解决所有的问题?
上述所有的问题都是 事务 并行执行引起的,所以改成所有事务依次执行(串行),当然所有问题就都解决了。
mysql的默认隔离级别是 repeatable read;
oracle的默认隔离级别是 read committed;
6 隔离级别的性能问题
性能比较:
serializable 性能最差,多个事务排队执行。
serializable < repeatable read < read committed < read uncommitted
安全性比较:
serializable 安全性能最好,所有问题都可以避免
serializable > repeatable read > read committed > read uncommitted
分析:
serializable 性能太差
read uncommitted 无法避免脏读,问题严重
总结:数据库厂商 选择了这种方案: 读已提交 和 可重复读
mysql 选择的可重复读 – repeatable read
oracle 选择 读已提交 – read committed
7 小结
1、事务:逻辑上的一组sql操作,要么全执行,要么全不执行。
3、事务的特性:(背诵加理解)
原子性、一致性、隔离性、持久性
4、如果不考虑隔离级别:(理解 并且能说出来)
脏读
不可重复读
虚读(幻读)
第四章 java中的事务管理
| 开启事务: Connection.setAutoCommit(false) | |
|---|---|
| 执行sql语句群 | |
| 出现异常 事务回滚(撤销)事务结束 Connection.rollback(); | 无异常 事务提交(生效)事务结束 Connection.commit(); |
1 演示未添加事务
1
需求:a 向 b 转账 100元。(未添加事务)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
@Test
public void demo1() {
// 需求:a 向 b 转账 100元。(未添加事务)
Connection conn = null;
PreparedStatement stmt = null;
try {
// 获取连接
conn = JDBCUtils.getConnection();
// a-100
// 获得发送sql的对象
String sql = "update account set money=money-100 where name='a'";
stmt = conn.prepareStatement(sql);
// 发送sql 获得结果
stmt.executeUpdate();
// b+100
// 获得发送sql的对象
String sql2 = "update account set money=money+100 where name='b'";
stmt = conn.prepareStatement(sql2);
// 发送sql 获得结果
stmt.executeUpdate();
System.out.println("一切ok");
} catch (Exception e) {
e.printStackTrace();
System.out.println("出现异常");
} finally {
JDBCUtils.release(conn, stmt);
}
}
2 演示添加事务
1
需求:a 向 b 转账 100元, 模拟异常。(强调事务的重要性:要么全执行,要么全撤销。)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
@Test
public void demo2() {
// 需求:a 向 b 转账 100元, 模拟异常。(强调事务的重要性:要么全执行,要么全撤销。)
Connection conn = null;
PreparedStatement stmt = null;
try {
// int j = 1 / 0;
// 获取连接
conn = JDBCUtils.getConnection();
// 开启事务
conn.setAutoCommit(false);
// a-100
// 获得发送sql的对象
String sql = "update account set money=money-100 where name='a'";
stmt = conn.prepareStatement(sql);
// 发送sql 获得结果
stmt.executeUpdate();
// b+100
// 获得发送sql的对象
String sql2 = "update account set money=money+100 where name='b'";
stmt = conn.prepareStatement(sql2);
// 发送sql 获得结果
stmt.executeUpdate();
int j = 1 / 0;
System.out.println("一切ok, 提交事务");
conn.commit();
} catch (Exception e) {
e.printStackTrace();
System.out.println("出现异常,回滚事务");
try {
if (conn != null) {
conn.rollback();
}
} catch (Exception e1) {
e1.printStackTrace();
}
} finally {
JDBCUtils.release(conn, stmt);
}
}
- 注意事项
- 1、Connection 和 PrepareStatement 对象引入时,必须是 java.sql 包下的。
- 2、开启事务 conn.setAutoCommit(false) 必须在 Connection对象获取之后。
- 3、抓异常时,最好选得大一些。因为 数/0 报的是 算术异常,不在sql异常范围内,所以最好改成Exception。
3 DBUtils事务操作
| Connection对象的方法名 | 描述 |
|---|---|
| conn.setAutoCommit(false) | 开启事务 |
| new QueryRunner() | 创建核心类,不设置数据源(手动管理连接) |
| query(conn , sql , handler, params ) 或 update(conn, sql , params) | 手动传递连接, 执行SQL语句CRUD |
| DbUtils.commitAndCloseQuietly(conn) | 提交并关闭连接,不抛异常 |
| DbUtils.rollbackAndCloseQuietly(conn) | 回滚并关闭连接,不抛异常 |
代码演示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
/*
DBUtils 的事务操作
*/
public class TransactionDemo2 {
/*
1.获得连接
2.开始事务
3.具体的sql操作(加钱, 减钱)
4.提交事务 ,释放资源
5.如果出现异常, 回滚事务释放资源
*/
@Test
public void test1() throws SQLException {
Connection conn = null;
try {
//1.获得连接
conn = DruidUtils.getConnetion();
// 2.开始事务
conn.setAutoCommit(false);
// 3.具体的sql操作(加钱, 减钱)
QueryRunner qr = new QueryRunner();
//减钱
String sql = "update account set money=money-? where name=?";
qr.update(conn, sql, 1000, "jack");
//模拟错误
int n =1/0;
//加钱
sql = "update account set money=money+? where name=?";
qr.update(conn, sql, 1000, "rose");
//4.提交事务 ,释放资源
DbUtils.commitAndCloseQuietly(conn);
} catch (Exception e) {
e.printStackTrace();
//5.如果出现异常, 回滚事务释放资源
DbUtils.rollbackAndCloseQuietly(conn);
}
}
}