共享模型之无锁
ch6 共享模型之无锁
CAS 与 Volatile
引入的例子
用的 AtomicInteger 的解决方法,内部并没有用锁来保护共享变量的线程安全。
那么它是如何实现的呢?
1
2
3
4
5
6
7
8
9
10
public void withdraw(Integer amount) {
while (true) {
while (true) {
int prev = balance.get();
int next = prev - amount;
if (balance.compareAndSet(prev, next))
break;
} // end while
} // end while
} // end withdraw
其中的关键是 compareAndSet,它的简称就是 CAS (也有 Compare And Swap 的说法),它必须是原子操作。
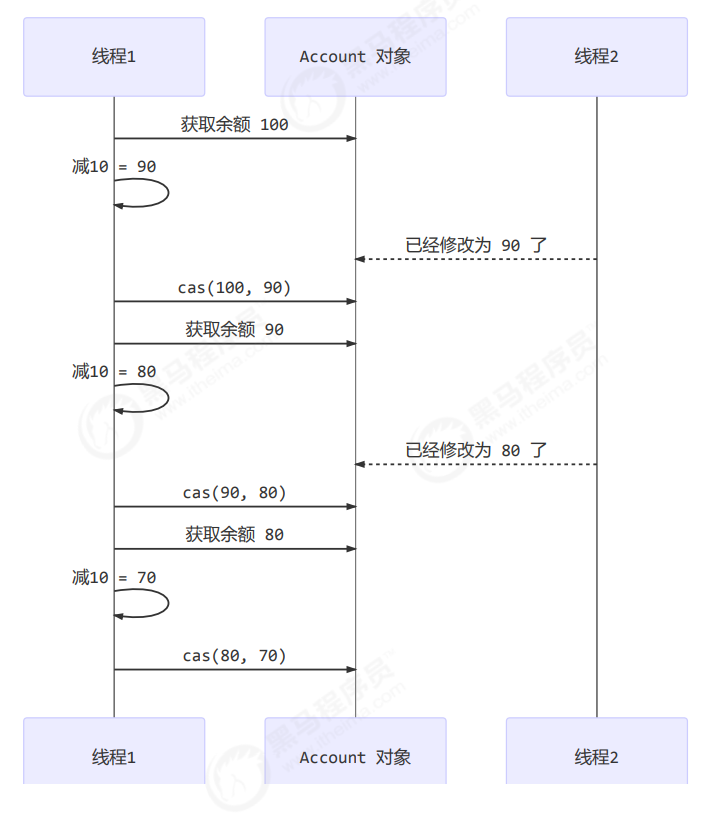
注意 其实 CAS 的底层是 lock cmpxchg 指令(X86架构),在单核 CPU 和多核 CPU 下都能保证【比较-交换】的原子性。
在多核状态下,某个核执行到带 lock 的指令时,CPU 会让总线锁住,当这个核把此指令执行完毕,再开启总线。这个过程中不会被线程的调度机制所打断,保证了多个线程对内存操作的准确性,是原子的。
volatile 关键字
获取共享变量时,为了保证该变量的可见性,需要使用 volatile 修饰。
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是之间操作主存。即一个线程对 volatile 变量的修改,对另一个线程可见。
注意 volatile 仅仅保证了共享变量的可见性,让其它线程能够看到最新值,但不能解决指令交错问题(不能保证原子性)
CAS 必须借助 volatile 才能读取到共享变量的最新值来实现 【比较并交换】的效果
为什么无锁效率高?
- 无锁情况下,即使重试失败,线程始终在高速运行,没有停歇,而 synchronized 会让线程在没有获得锁的时候,发生上下文切换,进入阻塞。
- 打个比喻,线程好像高速跑道上的赛车,高速运行时,速度超快,一但发生上下文切换,就好比赛车要减速、熄火,等被唤醒又得重新打火、启动、加速…恢复到高速运行,代价比较大
- 但无锁情况下,因为线程要保持运行,需要额外 CPU 的支持,CPU 在这里就好比高速跑道,没有额外的跑道,线程想高速运行也无从谈起,虽然不会进入阻塞,但由于没有分到时间片,仍然会进入可运行状态,还是会导致上下文切换。
CAS 的特点
结合 CAS 和 volatile 可以实现无锁并发,适用于线程数少、多核 CPU 的场景下。
- CAS 是基于乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,就算改了也没关系,我吃亏点再重试呗。
- synchronized 是基于悲观锁的思想:最悲观的估计,得防着其它线程来修改共享变量,我上了锁你们都别想改,我改完了解开锁,你们才有机会。
- CAS 体现的是无锁并发、无阻塞并发,请仔细体会这两句话的意思
- 因为没有使用 synchronized ,所以线程不会陷入阻塞,这时效率提升的因素之一
- 但如果竞争激烈,可以想到重试必然频繁发生,反而效率会受影响
高性能 CAS 处理机制
- compareAndSet()数据修改操作方法在 J.U.C 中被称为CAS机制,CAS(Compare-And-swap)是一条 CPU 并发原语(是CPU 的原生指令,是直接写在 CPU 内部的程序代码)。它的功能是判断内存某个位置的值是否为预期值,如果是则更改为新的值反之则不进行修改,这个过程属于原子性操作。
- 在多线程进行数据修改时,为了保证数据修改的正确性,常规的做法就是使用synchronized 同步锁,但是这种锁属于“悲观锁(Pessimistic Lock)”,每一个线程都需要在操作之前锁定当前的内存区域,而后才可以进行处理,这样一来在高并发环境下就会严重影响到程序的处理性能。
- 而 CAS 采用的是一种“乐观锁”(Optimistic Lock)机制,其最大的操作特点是不进行强制性的同步处理(没有 synchronized)而为了保证数据修改的正确性,添加了一些比较的数据(例如:compareAndset()在修改之前需要进行数据的比较),采用的是-种冲突重试的处理机制,这样可以有效的避免线程阻塞问题的出现。在并发竟争不是很激烈的情况下,可以获得较好的处理性能,而在 JDK 1.9 后为了进一步提升 CAS 的操作性能,又追加了硬件处理指令集的支持,可以充分的发挥服务器硬件配置的优势,得到更好的处理性能。
原子整数
J.U.C 并发包提供了:
- AtomicBoolean
- AtomicInteger
- AtomicLong
以 AtomicInteger 为例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
AtomicInteger i = new AtomicInteger(0);
// 获取并自增(i = 0, 结果 i = 1, 返回 0),类似于 i++
System.out.println(i.getAndIncrement());
// 自增并获取(i = 1, 结果 i = 2, 返回 2),类似于 ++i
System.out.println(i.incrementAndGet());
// 自减并获取(i = 2, 结果 i = 1, 返回 1),类似于 --i
System.out.println(i.decrementAndGet());
// 获取并自减(i = 1, 结果 i = 0, 返回 1),类似于 i--
System.out.println(i.getAndDecrement());
// 获取并加值(i = 0, 结果 i = 5, 返回 0)
System.out.println(i.getAndAdd(5));
// 加值并获取(i = 5, 结果 i = 0, 返回 0)
System.out.println(i.addAndGet(-5));
// 获取并更新(i = 0, p 为 i 的当前值, 结果 i = -2, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
System.out.println(i.getAndUpdate(p -> p - 2));
// 更新并获取(i = -2, p 为 i 的当前值, 结果 i = 0, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
System.out.println(i.updateAndGet(p -> p + 2));
// 获取并计算(i = 0, p 为 i 的当前值, x 为参数1, 结果 i = 10, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
// getAndUpdate 如果在 lambda 中引用了外部的局部变量,要保证该局部变量是 final 的
// getAndAccumulate 可以通过 参数1 来引用外部的局部变量,但因为其不在 lambda 中因此不必是 final
System.out.println(i.getAndAccumulate(10, (p, x) -> p + x));
// 计算并获取(i = 10, p 为 i 的当前值, x 为参数1, 结果 i = 0, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
System.out.println(i.accumulateAndGet(-10, (p, x) -> p + x));
原子引用
为什么需要原子引用类型?
- AtomicReference
- AtomicMarkableReference
- AtomicStampedReference
比较 AtomicInteger 是对整数的封装,而 AtomicReference 则是对应普通的对象引用,也就是它可以保证你在修改对象引用时的线程安全性。
ABA 问题及解决
ABA问题
假如线程I使用 CAS 修改初始值为 A 的变量 X,那么线程I会首先去获取当前变量 X 的值(为 A),然后使用 CAS 操作尝试修改 X 值为 B,如果使 CAS 操作成功了,那么程序运行一定是正确的吗?
其实未必,这是因为有可能在线程I获取变量 X 的值 A 后,在执行 CAS 前,线程II使用 CAS 修改了变量 X 的值为 B,然后又使 CAS 修改变量 X 的值为 A。
所以虽然线程I执行 CAS 时 X 的值是 A,但是这 A 己经不是线程I获取时的 A 了。这就是 ABA 问题。
ABA 产生是因为变量的状态值产生了环形转换,就是变量的值可以从 A 到 B,然后再从 B 到 A。如果变量的值只能朝着一个方向转换,比如 A 到 B,B 到 C,不构成环形,就不会存在问题。
JDK 中的 AtomicStampedReference 类给每个变量的状态值都配备了一个时间戳避免了 ABA 问题的产生。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
static AtomicReference<String> ref = new AtomicReference<>("A");
public static void main(String[] args) throws InterruptedException {
log.debug("main start...");
// 获取值 A
// 这个共享变量被它线程修改过?
String prev = ref.get();
other();
sleep(1);
// 尝试改为 C
log.debug("change A->C {}", ref.compareAndSet(prev, "C"));
}
private static void other() {
new Thread(() -> {
log.debug("change A->B {}", ref.compareAndSet(ref.get(), "B"));
}, "t1").start();
sleep(0.5);
new Thread(() -> {
log.debug("change B->A {}", ref.compareAndSet(ref.get(), "A"));
}, "t2").start();
}
主线程仅能判断出共享变量的值与最初值 A 是否相同,不能感知到这种 A 改回 B 又改回 A 的情况,如果主线程希望:
只要有其它线程【动过了】共享变量,那么自己的 CAS 就算失败,这时仅比较值是不够的,需要再加一个版本号
AtomicReference 对象在修改过程中丢失了状态信息,对象值本身与状态画上了等号。
所以说我们只要能够记录对象在修改过程中的状态值,就可以很好地解决对象被反复修改导致线程无法正确判断对象状态的问题。
AtomicStampedReference
AtomicStampedReference 内部不仅维护了对象值,还维护了一个时间戳;其设置对象值时,对象值及时间戳都必须满足期望值,写入才会成功;即使对象值被反复读写,写回原值,只要时间戳发生变化,就能防止不恰当的写入。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
static AtomicStampedReference<String> ref = new AtomicStampedReference<>("A", 0);
public static void main(String[] args) throws InterruptedException {
log.debug("main start...");
// 获取值 A
String prev = ref.getReference();
// 获取版本号
int stamp = ref.getStamp();
log.debug("版本 {}", stamp);
// 如果中间有其它线程干扰,发生了 ABA 现象
other();
sleep(1);
// 尝试改为 C
log.debug("change A->C {}", ref.compareAndSet(prev, "C", stamp, stamp + 1));
}
private static void other() {
new Thread(() -> {
log.debug("change A->B {}", ref.compareAndSet(ref.getReference(), "B",
ref.getStamp(), ref.getStamp() + 1));
log.debug("更新版本为 {}", ref.getStamp());
}, "t1").start();
sleep(0.5);
new Thread(() -> {
log.debug("change B->A {}", ref.compareAndSet(ref.getReference(), "A",
ref.getStamp(), ref.getStamp() + 1));
log.debug("更新版本为 {}", ref.getStamp());
}, "t2").start();
}
AtomicStampedReference 可以给原子引用加上版本号,追踪原子引用整个变化过程,如 A -> B -> A -> C,通过 AtomicStampedReference ,我们可以知道引用变量中途被改了几次。
AtomicMarkableReference
但是有时候,并不关心引用变量更改了几次,只是单纯的关心是否更改过,所以就有了 AtomicMarkableReference
原子数组
- AtomicIntegerArray
- AtomicLongArray
- AtomicReferenceArray
字段更新器
- AtomicReferenceFieldUpdater // 域 字段
- AtomicIntegerFieldUpdater
- AtomicLongFieldUpdater
利用字段更新器,可针对对象的某个域(Field)进行原子操作,只能配合 volatile 修饰的字段使用,否则会出现异常
1
Exception in thread "main" java.lang.IllegalArgumentException: Must be volatile type
原子累加器 LongAdder()
LongAdder 类有几个关键域
1
2
3
4
5
6
7
// 累加单元数组, 懒惰初始化
transient volatile Cell[] cells;
// 基础值, 如果没有竞争, 则用 cas 累加这个域
transient volatile long base;
// 在 cells 创建或扩容时, 置为 1, 表示加锁
transient volatile int cellsBusy;
原理之伪共享
累加主要调用下面的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
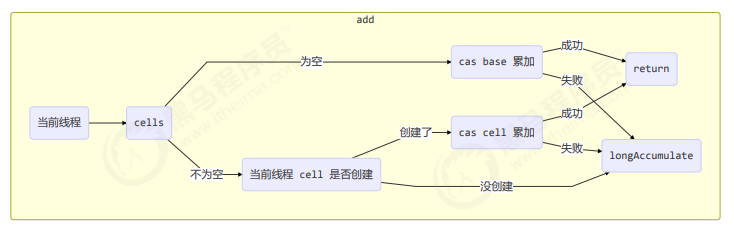
public void add(long x) {
// as 为累加单元数组
// b 为基础值
// x 为累加值
Cell[] as; long b, v; int m; Cell a;
// 进入 if 的两个条件
// 1. as 有值, 表示已经发生过竞争, 进入 if
// 2. cas 给 base 累加时失败了, 表示 base 发生了竞争, 进入 if
if ((as = cells) != null || !casBase(b = base, b + x)) {
// uncontended 表示 cell 没有竞争
boolean uncontended = true;
if (
// as 还没有创建
as == null || (m = as.length - 1) < 0 ||
// 当前线程对应的 cell 还没有
(a = as[getProbe() & m]) == null ||
// cas 给当前线程的 cell 累加失败 uncontended=false ( a 为当前线程的 cell )
!(uncontended = a.cas(v = a.value, v + x))
) {
// 进入 cell 数组创建、cell 创建的流程
longAccumulate(x, null, uncontended);
}
}
}
add 流程图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
// 当前线程还没有对应的 cell, 需要随机生成一个 h 值用来将当前线程绑定到 cell
if ((h = getProbe()) == 0) {
// 初始化 probe
ThreadLocalRandom.current();
// h 对应新的 probe 值, 用来对应 cell
h = getProbe();
wasUncontended = true;
}
// collide 为 true 表示需要扩容
boolean collide = false;
for (;;) {
Cell[] as; Cell a; int n; long v;
// 已经有了 cells
if ((as = cells) != null && (n = as.length) > 0) {
// 还没有 cell
if ((a = as[(n - 1) & h]) == null) {
// 为 cellsBusy 加锁, 创建 cell, cell 的初始累加值为 x
// 成功则 break, 否则继续 continue 循环
}
// 有竞争, 改变线程对应的 cell 来重试 cas
else if (!wasUncontended)
wasUncontended = true;
// cas 尝试累加, fn 配合 LongAccumulator 不为 null, 配合 LongAdder 为 null
else if (a.cas(v = a.value, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
break;
// 如果 cells 长度已经超过了最大长度, 或者已经扩容, 改变线程对应的 cell 来重试 cas
else if (n >= NCPU || cells != as)
collide = false;
// 确保 collide 为 false 进入此分支, 就不会进入下面的 else if 进行扩容了
else if (!collide)
collide = true;
// 加锁
else if (cellsBusy == 0 && casCellsBusy()) {
// 加锁成功, 扩容
continue;
}
// 改变线程对应的 cell
h = advanceProbe(h);
}
// 还没有 cells, 尝试给 cellsBusy 加锁
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
// 加锁成功, 初始化 cells, 最开始长度为 2, 并填充一个 cell
// 成功则 break;
}
// 上两种情况失败, 尝试给 base 累加
else if (casBase(v = base, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
break;
}
}
longAccumulate 流程图
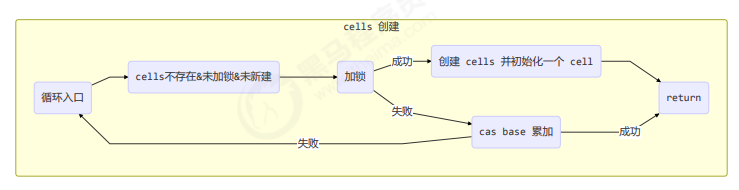
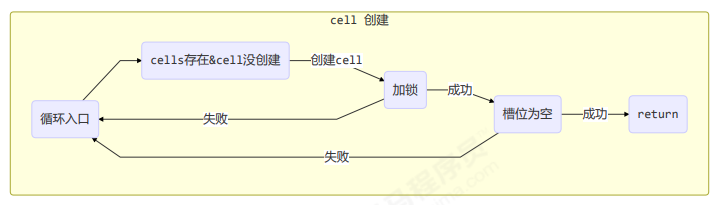
每个线程刚进入 longAccumulate 时,会尝试对应一个 cell 对象(找到一个坑位)
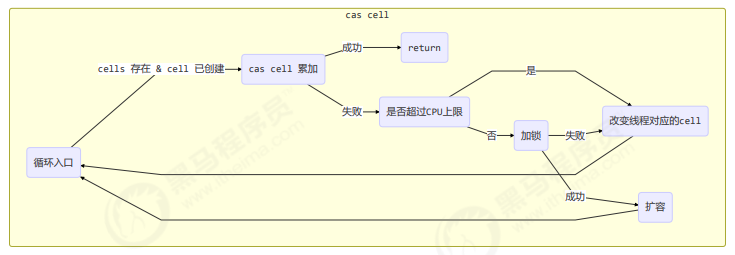
获取最终结果通过 sum 方法
1
2
3
4
5
6
7
8
9
10
11
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
Unsafe
Unsafe 对象提供了非常底层的,操作内存、线程的方法,Unsafe 对象不能直接调用,只能通过反射获得
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class UnsafeAccessor {
static Unsafe unsafe;
static {
try {
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
unsafe = (Unsafe) theUnsafe.get(null);
} catch (NoSuchFieldException | IllegalAccessException e) {
throw new Error(e);
}
}
static Unsafe getUnsafe() {
return unsafe;
}
}
ch6 本章总结 如图
