Python 抓取m3u8视频
抓取m3u8视频
1、思路分析
视频url:https://www.9tata.cc/play/96310-4-0.html
上面那个资源被删了,笑死了 https://www.9tata.cc/play/13408-0-0.html
- 打开网址分析当前视频是由多个片段组成还是单独一个视频 如果是一个单独视频,则找到网址,直接下载即可,如果为多个片段的视频,则需要找到片段的文件进行处理,本案例以m3u8为例
- 找到m3u8文件后进行下载,下载后打开文件分析是否需要秘钥,需要秘钥则根据秘钥地址进行秘钥下载,然后下载所有ts文件
- 合并所有视频
2、实现
分析index.m3u8
通过网络查找发现有俩个m3u8文件
url分别为
https://ikcdn01.ikzybf.com/20230105/sidUNS3Y/index.m3u8
https://ikcdn01.ikzybf.com/20230105/sidUNS3Y/2000kb/hls/index.m3u8
通过分析 第一个index.m3u8请求返回的内容中包含了第二个m3u8请求的url地址
也就是说通过第一个index.m3u8url请求返回包含第二个index.m3u8文件地址,通过拼接请求第二个index.m3u8后 返回了包含当前所有ts文件的地址内容
现在分析出了第二个真正的index.m3u8的地址,但是第一个地址从哪里来的呢,别慌,接下来我们来查找一下第一个url是从哪里来的
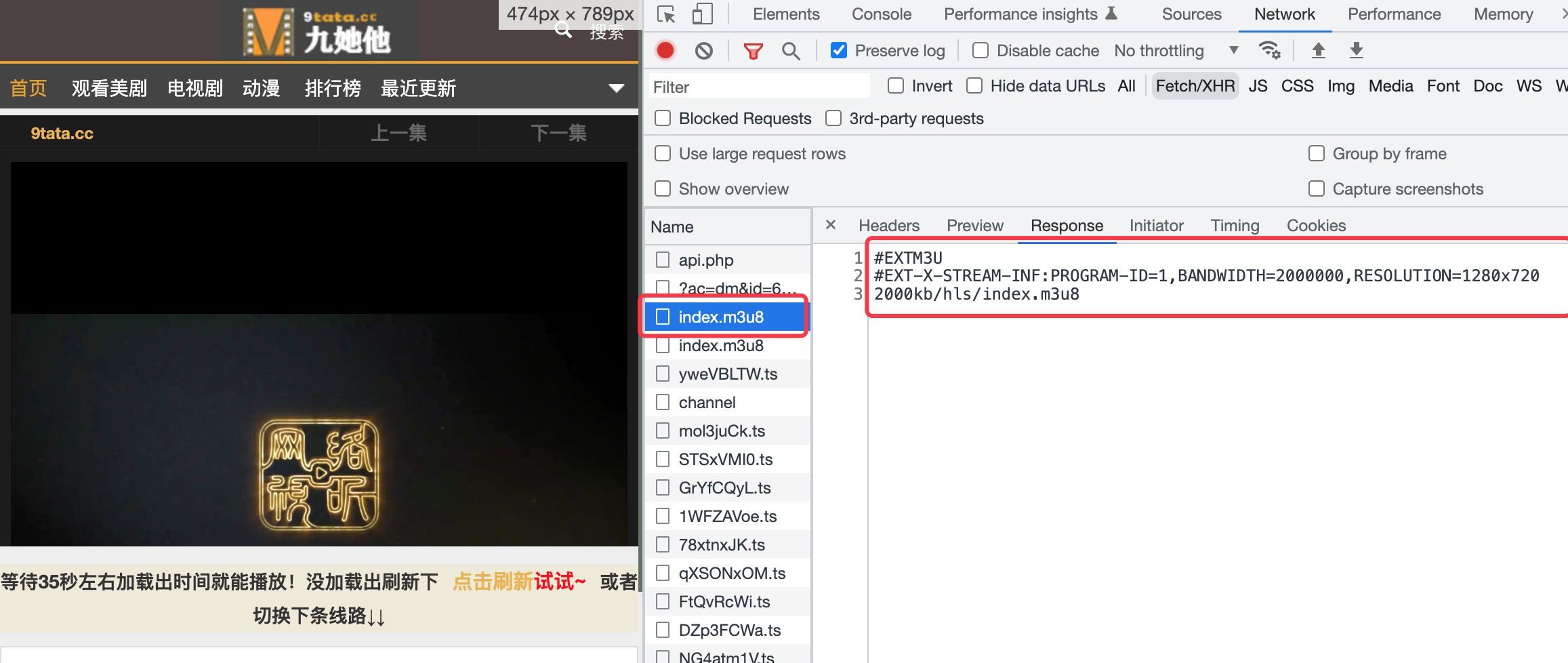
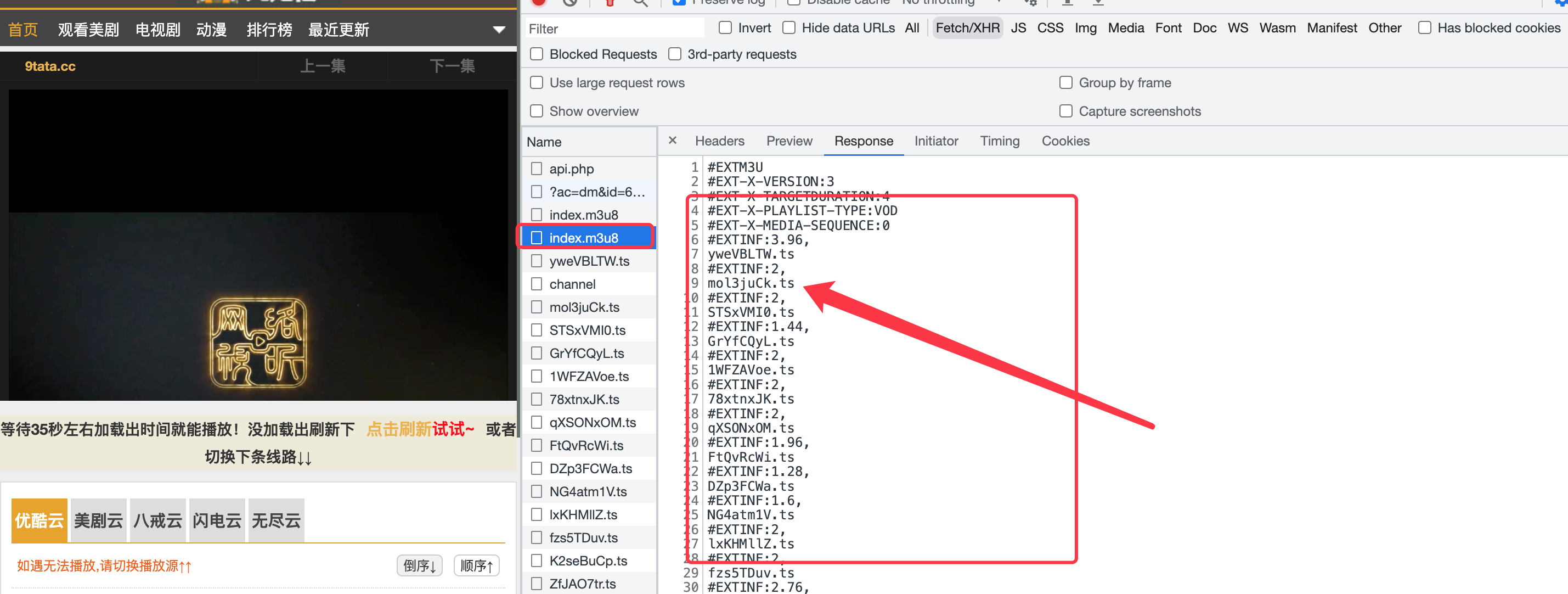
查找第一个index.m3u8的url地址
打开source
发现url存在页面源代码中的js里 知道了位置,在代码中通过正则匹配就可以获取到了
现在我们缕一下思路,通过页面源代码可以找到第一个index.m3u8的url,通过请求返回包含第二个index.m3u8文件的url内容,进行拼接,请求第二个m3u8的url,以此返回所有的ts内容
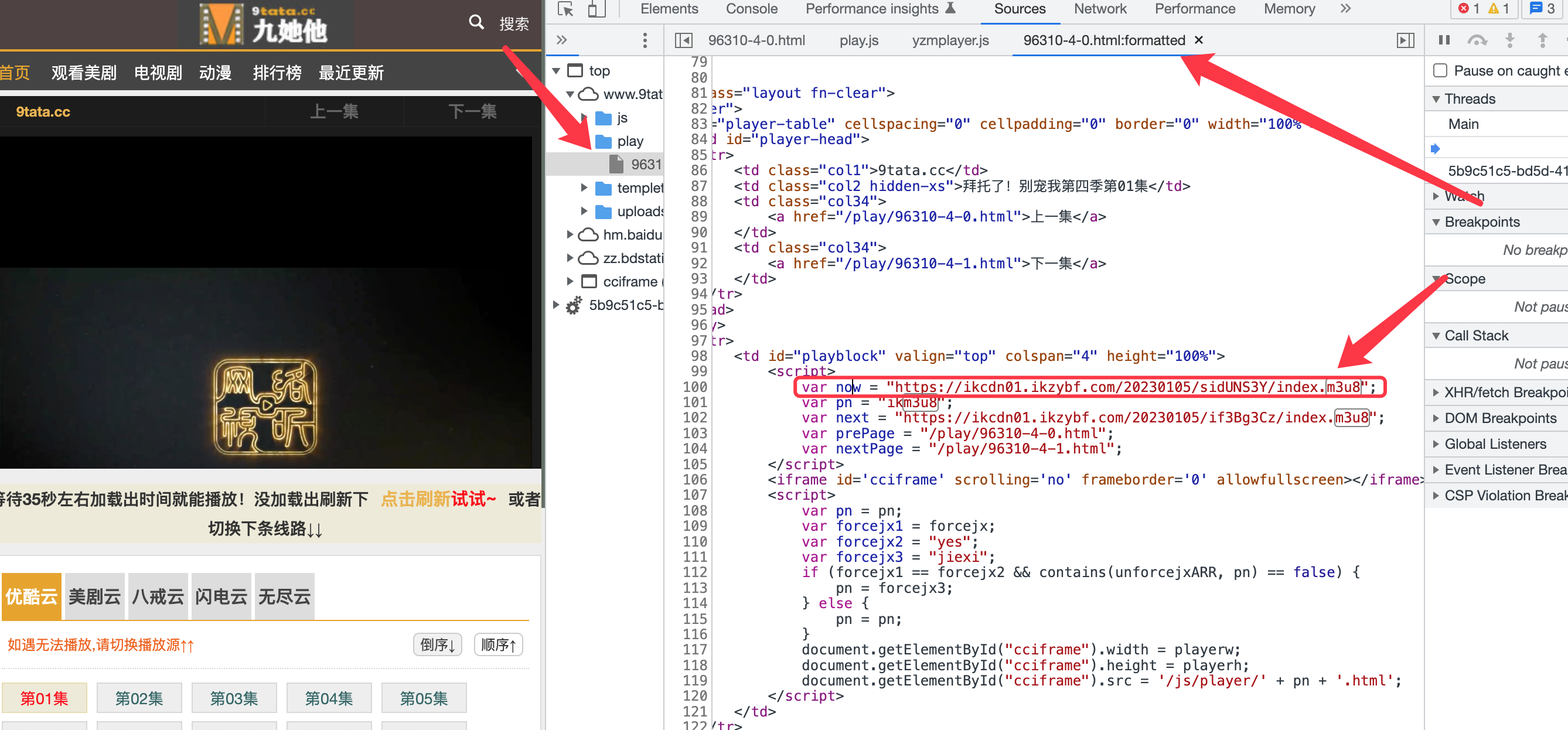
3、代码实现
3.1 获取最后一个m3u8的url的内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
import re
from urllib.parse import urljoin
import urllib3
import requests
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
session = requests.Session()
session.get('https://www.9tata.cc/', headers=headers, verify=False)
url = 'https://www.9tata.cc/play/96310-4-0.html'
response = session.get(url, headers=headers, verify=False)
response.encoding = 'UTF-8'
data = response.text
"""
with open('data.html', 'w', encoding='UTF-8') as f:
# 写入response.content bytes二进制类型
f.write(data)
# 读取页面内容
with open('data.html', 'r', encoding='UTF-8') as f:
# 写入response.content bytes二进制类型
data = f.read()
"""
# m3u8的url在页面中的内容
# var now="https://ikcdn01.ikzybf.com/20230105/sidUNS3Y/index.m3u8"
m3u8_url = re.search('var now="(.+?index.m3u8)"', data).group(1).replace('\\', '')
# 请求可以获取index.m3u8文件
response = session.get(m3u8_url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
"""
with open('first_m3u8.text', 'w', encoding='UTF-8') as f:
# 写入response.content bytes二进制类型
f.write(data)
# 读取第一次m3u8文件内容
with open('first_m3u8.text', 'r', encoding='UTF-8') as f:
# 写入response.content bytes二进制类型
data = f.read()
"""
'''
index.m3u8.txt
#EXTM3U
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=2000000,RESOLUTION=1280x720
2000kb/hls/index.m3u8
# 第1,2次m3u8的URL
https://ikcdn01.ikzybf.com/20230105/sidUNS3Y/index.m3u8
https://ikcdn01.ikzybf.com/20230105/sidUNS3Y/2000kb/hls/index.m3u8
'''
# 拆分返回的内容获取真整的index.m3u8文件的url
# \n2000kb/hls/index.m3u8 前面有换行符\n
second_url = data.split('\n')[-1]
# 拼接最终m3u8的url
second_url = m3u8_url.rsplit('/', 1)[0] + '/' + second_url
# 开始最终的请求
response = session.get(second_url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
with open('index.m3u8', 'w', encoding='UTF-8') as f:
# 写入response.content bytes二进制类型
f.write(data)
3.1.1 进行封装
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
import requests
import re
from urllib.parse import urljoin
def get_m3u8_url(url):
'''
抓取页面中的index.m3u8的文件数据 写入到本地index.m3u8文件并返回m3u8url地址
:param url: 页面的url(要抓取的视频的页面url)
:return: url
'''
session = requests.Session()
session.get('https://www.9tata.cc/', headers=headers, verify=False)
response = session.get(url, headers=headers, verify=False)
response.encoding = 'UTF-8'
data = response.text
m3u8_url = re.search('var now="(.+?index.m3u8)"', data).group(1).replace('\\', '')
# 请求可以获取index.m3u8文件
response = session.get(m3u8_url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
second_url = data.split('\n')[-1]
# 拼接最终m3u8的url
second_url = m3u8_url.rsplit('/', 1)[0] + '/' + second_url
# 开始最终的请求
response = session.get(second_url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
with open('index.m3u8', 'w', encoding='UTF-8') as f:
# 写入response.content bytes二进制类型
f.write(data)
with open('index.m3u8', 'w', encoding='UTF-8') as f:
f.write(data)
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
url = 'https://www.9tata.cc/play/96310-4-0.html'
get_m3u8_url(url)
3.2 同步下载ts视频
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import os.path
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
# 读取index.m3u8文件 以列表形式返回每一行
with open('index.m3u8', 'r', encoding='UTF-8') as f:
lines = f.readlines()
path = 'ts' # 下载所有ts的文件的路径
if not os.path.exists(path):
os.mkdir(path)
# print(lines)
# 循环读取每一行数据
i = 0
for line in lines:
# 获取所有要下载的ts的url地址 不以#作为开头
if line.startswith('#'):
continue
# print(line)
# 进行下载处理
'''
yweVBLTW.ts
正常请求处理的ur 需要进行拼接处理
https://ikcdn01.ikzybf.com/20230105/sidUNS3Y/2000kb/hls/yweVBLTW.ts
'''
url = 'https://ikcdn01.ikzybf.com/20230105/sidUNS3Y/2000kb/hls/' + line.strip() # 去除请求的url中可能包含的其他的字符
res = requests.get(url, headers=headers)
# 拼接下载文件的路径及下载后ts的文件名称
file_path = os.path.join(path, str(i)+'.ts')
# 进行下载写入
with open(file_path, 'wb') as f:
f.write(res.content)
i += 1
3.2.1 封装
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
import os.path
import requests
def dowload_one_m3u8(url, i, path):
'''
下载单个ts文件的函数
:param url: 要下载ts的url地址
:param i: 当前的文件的名称 也就是i的循环自增
:param path: 当前下载后ts所需要存储的路径
:return:
'''
res = requests.get(url, headers=headers)
print(url, '正在下载')
# 拼接下载文件的路径及下载后ts的文件名称
file_path = os.path.join(path, str(i) + '.ts')
# 进行下载写入
with open(file_path, 'wb') as f:
f.write(res.content)
def download_all_m3u8(filename='index.m3u8'):
'''
下载所有的m3u8的里面的ts文件
:param filename: m3u8的文件名称
:return:
'''
# 读取index.m3u8文件 以列表形式返回每一行
with open(filename, 'r', encoding='UTF-8') as f:
lines = f.readlines()
path = 'ts' # 下载所有ts的文件的路径
if not os.path.exists(path):
os.mkdir(path)
# print(lines)
# 循环读取每一行数据
i = 0
for line in lines:
# 获取所有要下载的ts的url地址 不以#作为开头
if line.startswith('#'):
continue
# print(line)
# 进行下载处理
# 去除请求的url中可能包含的其他的字符 拼接url
url = 'https://ikcdn01.ikzybf.com/20230105/sidUNS3Y/2000kb/hls/' + line.strip()
dowload_one_m3u8(url, i, path)
i += 1
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
download_all_m3u8()
3.3 封装完整单进程下载
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
import os.path
import requests
import re
from urllib.parse import urljoin
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
def get_m3u8_url(url):
'''
抓取页面中的index.m3u8的文件数据 写入到本地index.m3u8文件并返回m3u8url地址
:param url: 页面的url(要抓取的视频的页面url)
:return: url
'''
session = requests.Session()
session.get('https://www.9tata.cc/', headers=headers, verify=False)
response = session.get(url, headers=headers, verify=False)
response.encoding = 'UTF-8'
data = response.text
m3u8_url = re.search('var now="(.+?index.m3u8)"', data).group(1).replace('\\', '')
# 请求可以获取index.m3u8文件
response = session.get(m3u8_url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
second_url = data.split('\n')[-1]
# 拼接最终m3u8的url
second_url = m3u8_url.rsplit('/', 1)[0] + '/' + second_url
# 开始最终的请求
response = session.get(second_url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
with open('index.m3u8', 'w', encoding='UTF-8') as f:
# 写入response.content bytes二进制类型
f.write(data)
with open('index.m3u8', 'w', encoding='UTF-8') as f:
f.write(data)
# 返回截取ts文件需要的前半部分的url
return second_url.rsplit('/', 1)[0]
def dowload_one_m3u8(urlw, i, path):
'''
下载单个ts文件的函数
:param url: 要下载ts的url地址
:param i: 当前的文件的名称 也就是i的循环自增
:param path: 当前下载后ts所需要存储的路径
:return:
'''
res = requests.get(url, headers=headers)
print(url, '正在下载')
# 拼接下载文件的路径及下载后ts的文件名称
file_path = os.path.join(path, str(i) + '.ts')
# 进行下载写入
with open(file_path, 'wb') as f:
f.write(res.content)
def download_all_m3u8(path, ts_url, filename='index.m3u8'):
'''
下载所有的m3u8的里面的ts文件
:param path: 存储下载ts文件的文件夹
:param filename: m3u8的文件名称
:return:
'''
# 读取index.m3u8文件 以列表形式返回每一行
with open(filename, 'r', encoding='UTF-8') as f:
lines = f.readlines()
# 判断 当前存储ts的文件目录是否存在 不存在则创建
if not os.path.exists(path):
os.mkdir(path)
# print(lines)
# 循环读取每一行数据
i = 0
for line in lines:
# 获取所有要下载的ts的url地址 不以#作为开头
if line.startswith('#'):
continue
# print(line)
# 进行下载处理
url = ts_url + '/' + line.strip() # 去除请求的url中可能包含的其他的字符
dowload_one_m3u8(url, i, path)
i += 1
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
url = 'https://www.9tata.cc/play/96310-4-0.html'
ts_url = get_m3u8_url(url)
path = 'ts' # 下载所有ts的文件的路径
download_all_m3u8(path, ts_url)
3.4 线程池下载
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
import os.path
import requests
import re
from urllib.parse import urljoin
from concurrent.futures import ThreadPoolExecutor, wait
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
def get_m3u8_url(url):
'''
抓取页面中的index.m3u8的文件数据 写入到本地index.m3u8文件并返回m3u8url地址
:param url: 页面的url(要抓取的视频的页面url)
:return: url
'''
session = requests.Session()
session.get('https://www.9tata.cc/', headers=headers, verify=False)
response = session.get(url, headers=headers, verify=False)
response.encoding = 'UTF-8'
data = response.text
m3u8_url = re.search('var now="(.+?index.m3u8)"', data).group(1).replace('\\', '')
# 请求可以获取index.m3u8文件
response = session.get(m3u8_url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
second_url = data.split('\n')[-1]
# 拼接最终m3u8的url
second_url = m3u8_url.rsplit('/', 1)[0] + '/' + second_url
# 开始最终的请求
response = session.get(second_url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
with open('index.m3u8', 'w', encoding='UTF-8') as f:
# 写入response.content bytes二进制类型
f.write(data)
with open('index.m3u8', 'w', encoding='UTF-8') as f:
f.write(data)
# 返回截取ts文件需要的前半部分的url
return second_url.rsplit('/', 1)[0]
def dowload_one_m3u8(url, i, path):
'''
下载单个ts文件的函数
:param url: 要下载ts的url地址
:param i: 当前的文件的名称 也就是i的循环自增
:param path: 当前下载后ts所需要存储的路径
:return:
'''
while True:
try:
res = requests.get(url, headers=headers, timeout=60)
print(url, '正在下载')
# 拼接下载文件的路径及下载后ts的文件名称
file_path = os.path.join(path, str(i) + '.ts')
# 进行下载写入
with open(file_path, 'wb') as f:
f.write(res.content)
print(url, '下载成功~')
break
except:
print(url, '请求超时~ 重新下载中')
def download_all_m3u8(path, ts_url, filename='index.m3u8'):
'''
下载所有的m3u8的里面的ts文件
:param path: 存储下载ts文件的文件夹
:param filename: m3u8的文件名称
:return:
'''
# 读取index.m3u8文件 以列表形式返回每一行
with open(filename, 'r', encoding='UTF-8') as f:
lines = f.readlines()
# 判断 当前存储ts的文件目录是否存在 不存在则创建
if not os.path.exists(path):
os.mkdir(path)
# print(lines)
# 创建线程池 并发下载
pool = ThreadPoolExecutor(100)
tasks = []
# 循环读取每一行数据
i = 0
for line in lines:
# 获取所有要下载的ts的url地址 不以#作为开头
if line.startswith('#'):
continue
# print(line)
# 进行下载处理
url = ts_url + '/' + line.strip() # 去除请求的url中可能包含的其他的字符
tasks.append(pool.submit(dowload_one_m3u8, url, i, path))
i += 1
# 集体等待
wait(tasks)
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
url = 'https://www.9tata.cc/play/96310-4-0.html'
ts_url = get_m3u8_url(url)
path = 'ts' # 下载所有ts的文件的路径
download_all_m3u8(path, ts_url)
3.5 处理index.m3u8中ts的url和下载后的ts文件的对应关系
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import os
def do_index_m3u8():
'''
将index.m3u8写入到ts文件夹内 将ts url改名为 0.ts 1.ts 目的是为了和ts文件中的ts文件进行对象
'''
with open('index.m3u8', 'r', encoding='UTF-8') as f:
lines = f.readlines()
path = 'ts'
# 判断 当前存储ts的文件目录是否存在 不存在则创建
if not os.path.exists(path):
os.mkdir(path)
# print(lines)
file_path = os.path.join(path, 'index.m3u8')
f = open(file_path, 'w', encoding='UTF-8')
i = 0
for line in lines:
# print(line)
# 获取所有要下载的ts的url地址 不以#作为开头
if line.startswith('#'):
f.write(line)
else:
f.write(str(i)+'.ts\n')
i += 1
do_index_m3u8()
3.6 多线程下载合并视频最终版本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
import os.path
import requests
import re
from urllib.parse import urljoin
from concurrent.futures import ThreadPoolExecutor, wait
def get_m3u8_url(url):
'''
抓取页面中的index.m3u8的文件数据 写入到本地index.m3u8文件并返回m3u8url地址
:param url: 页面的url(要抓取的视频的页面url)
:return: url
'''
session = requests.Session()
session.get('https://www.9tata.cc/', headers=headers, verify=False)
response = session.get(url, headers=headers, verify=False)
response.encoding = 'UTF-8'
data = response.text
m3u8_url = re.search('var now="(.+?index.m3u8)"', data).group(1).replace('\\', '')
# 请求可以获取index.m3u8文件
response = session.get(m3u8_url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
second_url = data.split('\n')[-1]
# 拼接最终m3u8的url
second_url = m3u8_url.rsplit('/', 1)[0] + '/' + second_url
# 开始最终的请求
response = session.get(second_url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
with open('index.m3u8', 'w', encoding='UTF-8') as f:
# 写入response.content bytes二进制类型
f.write(data)
with open('index.m3u8', 'w', encoding='UTF-8') as f:
f.write(data)
# 返回截取ts文件需要的前半部分的url
return second_url.rsplit('/', 1)[0]
def dowload_one_m3u8(url, i, path):
'''
下载单个ts文件的函数
:param url: 要下载ts的url地址
:param i: 当前的文件的名称 也就是i的循环自增
:param path: 当前下载后ts所需要存储的路径
:return:
'''
while True:
try:
res = requests.get(url, headers=headers, timeout=60)
print(url, '正在下载')
# 拼接下载文件的路径及下载后ts的文件名称
file_path = os.path.join(path, str(i) + '.ts')
# 进行下载写入
with open(file_path, 'wb') as f:
f.write(res.content)
print(url, '下载成功~')
break
except:
print(url, '请求超时~ 重新下载中')
def download_all_m3u8(path, ts_url, filename='index.m3u8'):
'''
下载所有的m3u8的里面的ts文件
:param path: 存储下载ts文件的文件夹
:param filename: m3u8的文件名称
:return:
'''
# 读取index.m3u8文件 以列表形式返回每一行
with open(filename, 'r', encoding='UTF-8') as f:
lines = f.readlines()
# 判断 当前存储ts的文件目录是否存在 不存在则创建
if not os.path.exists(path):
os.mkdir(path)
# print(lines)
# 创建线程池 并发下载
pool = ThreadPoolExecutor(100)
tasks = []
# 循环读取每一行数据
i = 0
for line in lines:
# 获取所有要下载的ts的url地址 不以#作为开头
if line.startswith('#'):
continue
# print(line)
# 进行下载处理
url = ts_url + '/' + line.strip() # 去除请求的url中可能包含的其他的字符
tasks.append(pool.submit(dowload_one_m3u8, url, i, path))
i += 1
# 集体等待
wait(tasks)
def do_index_m3u8(path, filename='index.m3u8'):
'''
将index.m3u8写入到ts文件夹内 将ts url改名为 0.ts 1.ts 目的是为了和ts文件中的ts文件进行对象
'''
with open(filename, 'r', encoding='UTF-8') as f:
lines = f.readlines()
# 判断 当前存储ts的文件目录是否存在 不存在则创建
if not os.path.exists(path):
os.mkdir(path)
# print(lines)
file_path = os.path.join(path, filename)
f = open(file_path, 'w', encoding='UTF-8')
i = 0
for line in lines:
# 获取所有要下载的ts的url地址 不以#作为开头
if line.startswith('#'):
f.write(line)
else:
f.write(str(i)+'.ts\n')
i += 1
def merge(path, filename='output'):
'''
进行ts文件合并 解决视频音频不同步的问题 建议使用这种
:param filePath:
:return:
'''
os.chdir(path) # 进入到ts文件夹 然后执行下面的命令
cmd = f'ffmpeg -i index.m3u8 -c copy {filename}.mp4'
os.system(cmd)
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
url = 'https://www.9tata.cc/play/96310-4-0.html'
ts_url = get_m3u8_url(url)
path = 'ts' # 下载所有ts的文件的路径
download_all_m3u8(path, ts_url)
do_index_m3u8(path) # 处理index.m3u8文件
path = 'ts' # 下载所有ts的文件的路径
merge(path) # 合并视频
# ts 下载后的样子
# 0.ts 1.ts 2.ts
3.7 协程下载合并视频最终版本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
import os.path
import re
from urllib.parse import urljoin
import aiohttp
import asyncio
import aiofiles
from aiohttp import TCPConnector
async def get_m3u8_url(url):
'''
抓取页面中的index.m3u8的文件数据 写入到本地index.m3u8文件并返回m3u8url地址
:param url: 页面的url(要抓取的视频的页面url)
:return: url
'''
async with aiohttp.ClientSession(connector=TCPConnector(ssl=False), headers=headers) as session:
async with session.get(url) as resp:
data = await resp.text(encoding='UTF-8')
# 这是抓取第一次的index.m3u8的地址
index_m3u8_url = re.search('var now="(.+?index.m3u8)"', data).group(1).replace('\\', '')
async with session.get(index_m3u8_url) as resp:
data = await resp.text(encoding='UTF-8')
second_url = data.split('\n')[-1]
index_m3u8_url = index_m3u8_url.rsplit('/', 1)[0] + '/' + second_url
# 请求第二个index.m3u8地址,当前返回的内容就是咱们真正获取ts文件的url
async with session.get(index_m3u8_url) as resp:
data = await resp.text(encoding='UTF-8')
async with aiofiles.open('index.m3u8', 'w', encoding='UTF-8') as f:
await f.write(data)
# 返回截取ts文件需要的前半部分的url
return index_m3u8_url.rsplit('/', 1)[0]
async def dowload_one_m3u8(url, i, path, sem):
'''
下载单个ts文件的函数
:param url: 要下载ts的url地址
:param i: 当前的文件的名称 也就是i的循环自增
:param path: 当前下载后ts所需要存储的路径
:return:
'''
while True:
# 使用信号量 控制并发
async with sem:
try:
async with aiohttp.ClientSession(connector=TCPConnector(ssl=False), headers=headers) as session:
print(url, '正在下载')
async with session.get(url, timeout=60) as resp:
data = await resp.read()
# 拼接下载文件的路径及下载后ts的文件名称
file_path = os.path.join(path, str(i) + '.ts')
# 进行下载写入
async with aiofiles.open(file_path, 'wb') as f:
await f.write(data)
print(url, '下载成功~')
break
except:
print(url, '请求超时~ 重新下载中')
async def download_all_m3u8(path, url, filename='index.m3u8'):
'''
下载所有的m3u8的里面的ts文件
:param path: 存储下载ts文件的文件夹
:param filename: m3u8的文件名称
:return:
'''
# 读取index.m3u8文件 以列表形式返回每一行
with open(filename, 'r', encoding='UTF-8') as f:
lines = f.readlines()
# 判断 当前存储ts的文件目录是否存在 不存在则创建
if not os.path.exists(path):
os.mkdir(path)
# print(lines)
# 创建信号量 并发下载
sem = asyncio.Semaphore(100)
tasks = []
# 循环读取每一行数据
i = 0
for line in lines:
# 获取所有要下载的ts的url地址 不以#作为开头
if line.startswith('#'):
continue
# print(line)
# 进行下载处理
ts_url = url + '/' + line.strip() # 去除请求的url中可能包含的其他的字符
tasks.append(asyncio.create_task(dowload_one_m3u8(ts_url, i, path, sem)))
i += 1
# 集体等待
await asyncio.wait(tasks)
def do_index_m3u8(path, filename='index.m3u8'):
'''
将index.m3u8写入到ts文件夹内 将ts url改名为 0.ts 1.ts 目的是为了和ts文件中的ts文件进行对象
'''
with open(filename, 'r', encoding='UTF-8') as f:
lines = f.readlines()
# 判断 当前存储ts的文件目录是否存在 不存在则创建
if not os.path.exists(path):
os.mkdir(path)
# print(lines)
file_path = os.path.join(path, filename)
f = open(file_path, 'w', encoding='UTF-8')
i = 0
for line in lines:
# 获取所有要下载的ts的url地址 不以#作为开头
if line.startswith('#'):
f.write(line)
else:
f.write(str(i)+'.ts\n')
i += 1
def merge(path, filename='output'):
'''
进行ts文件合并 解决视频音频不同步的问题 建议使用这种
:param filePath:
:return:
'''
os.chdir(path) # 进入到ts文件夹 然后执行下面的命令
cmd = f'ffmpeg -i index.m3u8 -c copy {filename}.mp4'
os.system(cmd)
async def main(url, path):
task = asyncio.create_task(get_m3u8_url(url))
url = await asyncio.gather(task)
# print(url)
task = asyncio.create_task(download_all_m3u8(path, url[0]))
await asyncio.gather(task)
do_index_m3u8(path) # 处理index.m3u8文件
merge(path, '拜托了') # 合并视频
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
url = 'https://www.9tata.cc/play/96310-4-0.html'
path = 'ts' # 下载所有ts的文件的路径
asyncio.run(main(url, path))
注意:当前视频合并所用的工具为ffmpeg 如需安装 查看我的另外一篇博客ffmpeg的使用
4、注意事项
4.1 说明
在获取index.m3u8文件的内容时,有的文件内容会显示…jpg/png的情况,并没显示…ts,那么遇到这种情况需要单独处理 内容如下:
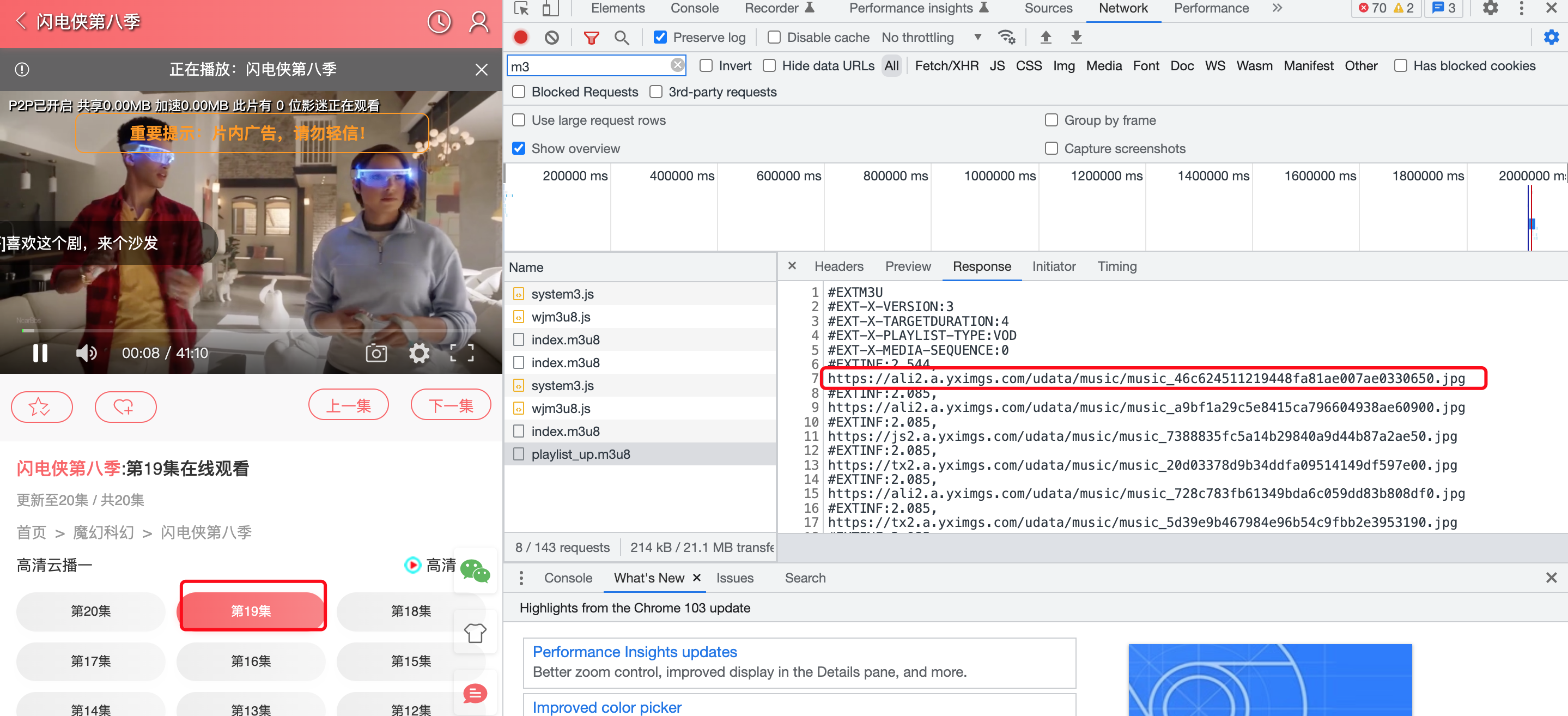
这种情况使用上面的代码就无法进行正常合并,合并后的视频无法播放
但使用ffprobe分析,发现识别为png,进而导致无法正常拼接
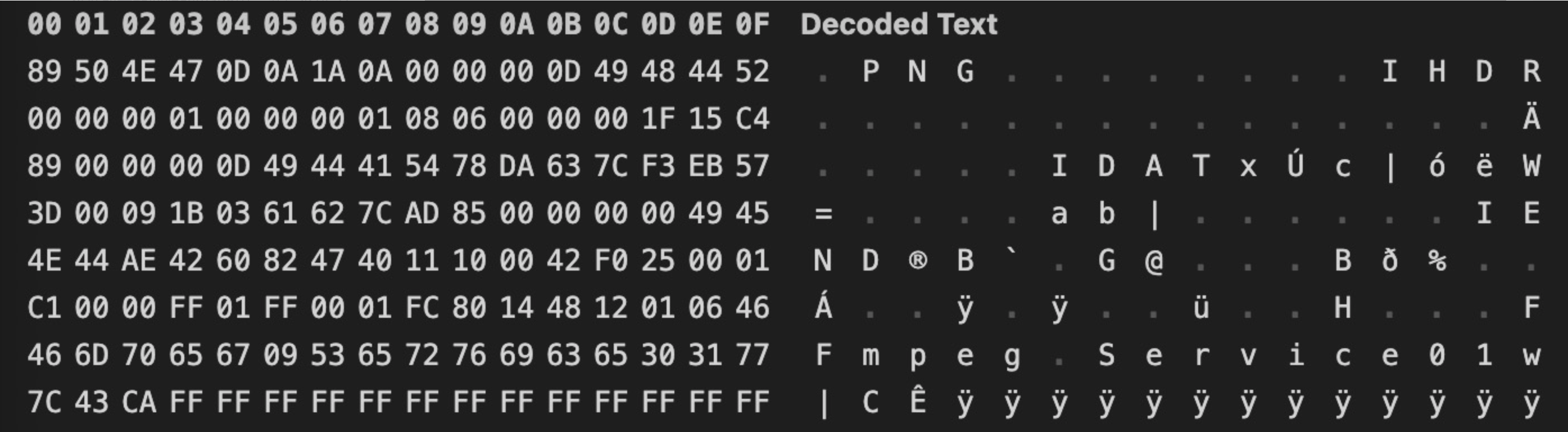
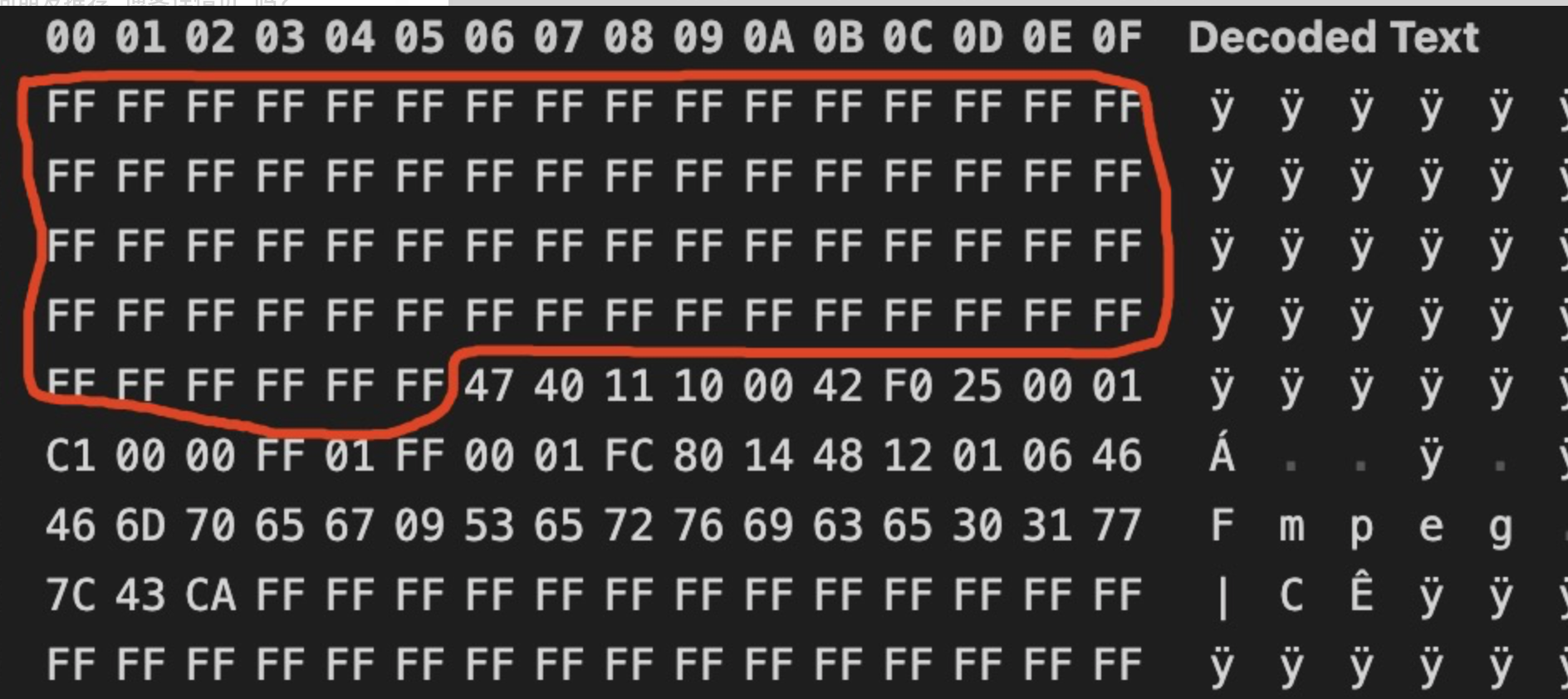
在这种情况下,只需要将其中PNG文件头部分全部使用FF填充,即可处理该问题
填充后的效果如图
4.2 使用代码进行处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 解析伪装成png的ts
def resolve_ts(src_path, dst_path):
'''
如果m3u8返回的ts文件地址为
https://p1.eckwai.com/ufile/adsocial/7ead0935-dd4f-4d2f-b17d-dd9902f8cc77.png
则需要下面处理后 才能进行合并
原因在于 使用Hexeditor打开后,发现文件头被描述为了PNG
在这种情况下,只需要将其中PNG文件头部分全部使用FF填充,即可处理该问题
:return:
'''
if not os.path.exists(dst_path):
os.mkdir(dst_path)
file_list = sorted(os.listdir(src_path), key=lambda x: int(x.split('.')[0]))
for i in file_list:
origin_ts = os.path.join(src_path, i)
resolved_ts = os.path.join(dst_path, i)
try:
infile = open(origin_ts, "rb") # 打开文件
outfile = open(resolved_ts, "wb") # 内容输出
data = infile.read()
outfile.write(data)
outfile.seek(0x00)
outfile.write(b'\xff\xff\xff\xff')
outfile.flush()
infile.close() # 文件关闭
outfile.close()
except:
pass
print('resolve ' + origin_ts + ' success')
4.3 完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
import shutil
import time
from urllib.parse import urljoin
import requests
import os
import re
from concurrent.futures import ThreadPoolExecutor, wait
def get_m3u8_url(url):
'''
获取页面中m3u8的url
:param url: 电影页面的url
:return:
'''
session = requests.Session()
# 访问首页获取cookie
session.get('https://www.9meiju.cc/', headers=headers)
# url = 'https://www.9meiju.cc/mohuankehuan/shandianxiadibaji/1-2.html'
response = session.get(url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
# print(data)
m3u8_uri = re.search('"url":"(.+?index.m3u8)"', data).group(1).replace('\\', '')
# 请求可以获取index.m3u8文件
response = session.get(m3u8_uri, headers=headers)
response.encoding = 'UTF-8'
data = response.text
# 拆分返回的内容获取真整的index.m3u8文件的url
# 注意 一定要strip
url = data.split('/', 3)[-1].strip()
print(data)
print('m3u8_uri', m3u8_uri)
url = urljoin(m3u8_uri, url)
print('url', url)
return url
def down_video(url, i):
'''
下载ts文件
:param url:
:param i:
:return:
'''
# print(url)
# 下载ts文件
resp = requests.get(url, headers=headers)
with open(os.path.join(path, str(i) + '.ts'), mode="wb") as f3:
f3.write(resp.content)
# print('{} 下载完成!'.format(url))
def download_all_videos(url, path):
'''
下载m3u8文件以及多线程下载ts文件
:param url:
:param path:
:return:
'''
# 请求m3u8文件进行下载
resp = requests.get(url, headers=headers)
with open("PycharmProjects/爬虫/day12-线程协程视频抓取最新版本/自己最新抓取视频/index.m3u8", mode="w", encoding="utf-8") as f:
f.write(resp.content.decode('UTF-8'))
if not os.path.exists(path):
os.mkdir(path)
# 开启线程 准备下载
pool = ThreadPoolExecutor(max_workers=50)
# 1. 读取文件
tasks = []
i = 0
with open("PycharmProjects/爬虫/day12-线程协程视频抓取最新版本/自己最新抓取视频/index.m3u8", mode="r", encoding="utf-8") as f:
for line in f:
# 如果不是url 则走下次循环
if line.startswith("#"):
continue
print(line, i)
# 开启线程
tasks.append(pool.submit(down_video, line.strip(), i))
i += 1
print(i)
# 统一等待
wait(tasks)
# 解析伪装成png的ts
def resolve_ts(src_path, dst_path):
'''
如果m3u8返回的ts文件地址为
https://p1.eckwai.com/ufile/adsocial/7ead0935-dd4f-4d2f-b17d-dd9902f8cc77.png
则需要下面处理后 才能进行合并
原因在于 使用Hexeditor打开后,发现文件头被描述为了PNG
在这种情况下,只需要将其中PNG文件头部分全部使用FF填充,即可处理该问题
:return:
'''
if not os.path.exists(dst_path):
os.mkdir(dst_path)
file_list = sorted(os.listdir(src_path), key=lambda x: int(x.split('.')[0]))
for i in file_list:
origin_ts = os.path.join(src_path, i)
resolved_ts = os.path.join(dst_path, i)
try:
infile = open(origin_ts, "rb") # 打开文件
outfile = open(resolved_ts, "wb") # 内容输出
data = infile.read()
outfile.write(data)
outfile.seek(0x00)
outfile.write(b'\xff\xff\xff\xff')
outfile.flush()
infile.close() # 文件关闭
outfile.close()
except:
pass
"""
else:
# 删除目录
shutil.rmtree(src_path)
# 将副本重命名为正式文件
os.rename(dst_path, dst_path.rstrip('2'))
"""
print('resolve ' + origin_ts + ' success')
# 处理m3u8文件中的url问题
def do_m3u8_url(path, m3u8_filename="index.m3u8"):
# 这里还没处理key的问题
if not os.path.exists(path):
os.mkdir(path)
with open(m3u8_filename, mode="r", encoding="utf-8") as f:
data = f.readlines()
fw = open(os.path.join(path, m3u8_filename), 'w', encoding="utf-8")
abs_path = os.getcwd()
i = 0
for line in data:
# 如果不是url 则走下次循环
if line.startswith("#"):
fw.write(line)
else:
fw.write(f'{abs_path}/{path}/{i}.ts\n')
i += 1
def merge(path, filename='output'):
'''
进行ts文件合并 解决视频音频不同步的问题 建议使用这种
:param filePath:
:return:
'''
os.chdir(path)
cmd = f'ffmpeg -i index.m3u8 -c copy {filename}.mp4'
os.system(cmd)
if __name__ == '__main__':
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36"
}
url = get_m3u8_url('https://www.9meiju.cc/mohuankehuan/shandianxiadibaji/1-20.html')
# 抓取99美剧闪电侠
# ts文件存储目录
path = 'ts'
# 下载m3u8文件以及ts文件
download_all_videos(url, path)
# 合并png的ts文件
src_path = path
dst_path = path + '2'
resolve_ts(src_path, dst_path)
do_m3u8_url(dst_path)
merge(dst_path, '闪电侠')
print('over')
5、解密处理
上面我们讲的是没有经过加密的 ts 文件,这些文件下载后直接可以播放,但经过AES-128加密后的文件下载后会无法播放,所以还需要进行解密。
如何判断是否需要加密?观察视频网站是否有m3u8的文件传输,下载下来并打开:
无需解密index.m3u8文件
1 2 3 4 5 6 7 8 9 10 11
#EXTM3U #EXT-X-VERSION:3 #EXT-X-TARGETDURATION:4 #EXT-X-PLAYLIST-TYPE:VOD #EXT-X-MEDIA-SEQUENCE:0 #EXTINF:3.086, https://hey05.cjkypo.com/20211215/FMbNtNzz/1100kb/hls/7qs6gJc0.ts #EXTINF:2.085, https://hey05.cjkypo.com/20211215/FMbNtNzz/1100kb/hls/rYpHhq0I.ts #EXTINF:2.085, https://hey05.cjkypo.com/20211215/FMbNtNzz/1100kb/hls/bfays5sw.ts
需要解密index.m3u8文件
index.m3u8:https://s7.fsvod1.com/20220622/5LnZiDXn/index.m3u8
1 2 3 4 5 6 7 8 9 10 11 12 13
#EXT-X-VERSION:3 #EXT-X-TARGETDURATION:1 #EXT-X-PLAYLIST-TYPE:VOD #EXT-X-MEDIA-SEQUENCE:0 #EXT-X-KEY:METHOD=AES-128,URI="/20220418/671fJxOB/2000kb/hls/key.key" # 当前路径为解密秘钥的位置 需要使用代码拼凑成完整路径 进行请求 域名+/20220418/671fJxOB/2000kb/hls/key.key #EXTINF:1.235, /20220418/671fJxOB/2000kb/hls/kj6uqHoP.ts # 并且这里ts的url也要拼凑完整 #EXTINF:1.001, /20220418/671fJxOB/2000kb/hls/ZXX8LYPa.ts #EXTINF:1.001, /20220418/671fJxOB/2000kb/hls/sOezpD2H.ts #EXTINF:1.001, ...
如果你的文件是加密的,那么你还需要一个key文件,Key文件下载的方法和m3u8文件类似,如下所示 key.key 就是我们需要下载的 key 文件,并注意这里 m3u8 有2个,需要使用的是像上面一样存在 ts 文件超链接的 m3u8 文件
下载所有 ts 文件,将下载好的所有的 ts 文件、m3u8、key.key 放到一个文件夹中,将 m3u8 文件改名为 index.m3u8,将 key.key 改名为 key.m3u8 。更改 index.m3u8 里的 URL,变为你本地路径的 key 文件,将所有 ts 也改为你本地的路径
文件路径
project/
ts/
0.ts
1.ts
…
index.m3u8
key.m3u8
修改后的index.m3u8内容如下所示:
1 2 3 4 5 6 7 8 9 10 11 12
#EXTM3U #EXT-X-VERSION:3 #EXT-X-TARGETDURATION:1 #EXT-X-PLAYLIST-TYPE:VOD #EXT-X-MEDIA-SEQUENCE:0 #EXT-X-KEY:METHOD=AES-128,URI="/Users/xialigang/PycharmProjects/爬虫/抓取带秘钥的电影/ts/key.m3u8" #EXTINF:1.235, /Users/xialigang/PycharmProjects/爬虫/抓取带秘钥的电影/ts/0.ts #EXTINF:1.001, /Users/xialigang/PycharmProjects/爬虫/抓取带秘钥的电影/ts/1.ts #EXTINF:1.001, /Users/xialigang/PycharmProjects/爬虫/抓取带秘钥的电影/ts/2.ts
处理index.m3u8内容的代码如下所示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117
import time from urllib.parse import urljoin import requests import os from concurrent.futures import ThreadPoolExecutor, wait import re headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36" } def down_video(url, i): ''' 下载ts文件 :param url: :param i: :return: ''' # print(url) # 下载ts文件 resp = requests.get(url, headers=headers) with open(os.path.join(path, str(i) + '.ts'), mode="wb") as f3: f3.write(resp.content) # print('{} 下载完成!'.format(url)) def download_all_videos(path, host): ''' 下载m3u8文件以及多线程下载ts文件 :param url: :param path: :return: ''' if not os.path.exists(path): os.mkdir(path) # 开启线程 准备下载 pool = ThreadPoolExecutor(max_workers=50) # 1. 读取文件 tasks = [] i = 0 with open("index.m3u8", mode="r", encoding="utf-8") as f: for line in f: # 如果不是url 则走下次循环 if line.startswith("#"): continue line = host + line print(line, i) # 开启线程 tasks.append(pool.submit(down_video, line.strip(), i)) i += 1 # 统一等待 wait(tasks) # 处理m3u8文件中的url问题 def do_m3u8url(url, path, m3u8filename="index.m3u8"): # 这里还没处理key的问题 if not os.path.exists(path): os.mkdir(path) with open(m3u8_filename, mode="r", encoding="utf-8") as f: data = f.readlines() fw = open(os.path.join(path, m3u8_filename), 'w') abs_path = os.getcwd() i = 0 for line in data: # 如果不是url 则走下次循环 if line.startswith("#"): # 判断处理是存在需要秘钥 if line.find('URI') != -1: line = re.sub('(#EXT-X-KEY:METHOD=AES-128,URI=")(.*?)"', f'\\1{os.path.join(abs_path, path)}/key.m3u8"', line) host = url.rsplit('/', 1)[0] # 爬取key download_m3u8(host + '/key.key', os.path.join(path, 'key.m3u8')) fw.write(line) else: fw.write(f'{abs_path}/{path}/{i}.ts\n') i += 1 def download_m3u8(url, m3u8_filename="index.m3u8", state=0): print('正在下载index.m3u8文件') resp = requests.get(url, headers=headers) with open(m3u8_filename, mode="w", encoding="utf-8") as f: f.write(resp.text) def merge(filePath, filename='output'): ''' 进行ts文件合并 解决视频音频不同步的问题 建议使用这种 :param filePath: :return: ''' os.chdir(path) cmd = f'ffmpeg -i index.m3u8 -c copy {filename}.mp4' os.system(cmd) def get_m3u8data(first_m3u8url): session = requests.Session() # 请求第一次m3u8de url resp = session.get(first_m3u8_url, headers=headers) resp.encoding = 'UTF-8' data = resp.text # 第二次请求m3u8文件地址 返回最终包含所有ts文件的m3u8 second_m3u8_url = urljoin(first_m3u8_url, data.split('/', 3)[-1].strip()) resp = session.get(second_m3u8_url, headers=headers) with open('index.m3u8', 'wb') as f: f.write(resp.content) return second_m3u8_url if __name__ == '__main__': # ts文件存储目录 path = 'ts' # 带加密的ts文件的 index.m3u8 url url = 'https://s7.fsvod1.com/20220622/5LnZiDXn/index.m3u8' meu8_url = get_m3u8_data(url) # 下载m3u8文件以及ts文件 host = 'https://s7.fsvod1.com' # 主机地址 用于拼凑完整的ts路径和秘钥路径 download_all_videos(path, host) do_m3u8_url(meu8_url, path) # 文件合并 merge(path, '奇异博士') print('over')
这样就大功告成了!我们成功解密并使用 ffmpeg 合并了这些 ts 视频片段,实际应用场景可能和这不一样,具体网站具体分析