正则表达式和三剑客
What is RegEx?
What is RegEx?
1
2
[root@server ~]# What is RegEx?
[root@server ~]# /(Reg[Ex])?/
- 正则表达式就是为了处理大量的字符串而定义的一套规则和方法。
- 通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤,替换或输出需要的字符串。
- Linux 正则表达式一般以行为单位处理的。
1
2
3
4
5
6
7
8
9
10
11
12
13
+----------------+ +------------------+ +----------------+
| | | | | |
| 数据流 |---->| 正则表达式 |---->| 匹配的数据 |
| | | | | |
+----------------+ +------------------+ +----------------+
|
|
v
+----------------+
| |
| 滤掉的数据 |
| |
+----------------+
正则表达式定义:
“正则表达式是你所定义的模式模板(pattern template),Linux工具可以用它来过滤文本。”
工具用途:
“Linux 工具(比如sed编辑器或gawk程序)能够在处理数据时使用正则表达式对数据进行模式匹配。”
匹配逻辑:
“如果数据匹配模式,它就会被接受并进一步处理;如果数据不匹配模式,它就会被滤掉。”
如何用正则表达式
通常Linux运维工作,都是面临大量带有字符串的内容,比如配置文件、程序代码、命令输出结果、日志文件;
且此类字符串内容,我们常会有特定的需要,查找出符合工作需要的特定的字符串,因此正则表达式就出现了
- 正则表达式是一套规则和方法;
- 正则工作时以单位进行,一次处理一行;
- 正则表达式化繁为简,提高工作效率;
- Linux仅受三剑客(sed、awk、grep)支持,其他命令无法使用。
学正则的注意事项
- 正则表达式应用非常广泛,很多编程语言都支持正则表达式,用于处理字符串提取数据;
- Linux下普通命令无法使用正则表达式的,只能使用Linux下的三个命令,结合正则表达式处理;
- sed
- grep
- awk
- 通配符是大部分普通命令都支持的,用于查找文件或目录;
- 而正则表达式是通过三剑客命令在文件(数据流)中过滤内容的,注意区别;
- 以及注意字符集,需要设置
LC_ALL=C,注意这一点很重要;
关于字符集设置
你会发现很多shell脚本里都有这么一个语句如下
1
2
3
4
5
6
[gest@node-110 ~]$ grep -Ri 'LC_ALL=C' /etc/init.d/
/etc/init.d/network: LC_ALL=C sed -e "$__sed_discard_ignored_files" \
/etc/init.d/network: LC_ALL=C sort -k 1,1 -k 2n | \
/etc/init.d/network: LC_ALL=C sed 's/ //')
[gest@node-110 ~]$
作用是修改Linux的字符集。
Linux通过locale命令可以查看本地字符集设置,通过如下变量设置程序运行的不同语言环境,如中文、英文环境。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
[root@server ~]# locale
LANG=en_US.UTF-8
LC_CTYPE="zh_CN.UTF-8"
LC_NUMERIC="zh_CN.UTF-8"
LC_TIME="zh_CN.UTF-8"
LC_COLLATE="zh_CN.UTF-8"
LC_MONETARY="zh_CN.UTF-8"
LC_MESSAGES="zh_CN.UTF-8"
LC_PAPER="zh_CN.UTF-8"
LC_NAME="zh_CN.UTF-8"
LC_ADDRESS="zh_CN.UTF-8"
LC_TELEPHONE="zh_CN.UTF-8"
LC_MEASUREMENT="zh_CN.UTF-8"
LC_IDENTIFICATION="zh_CN.UTF-8"
LC_ALL=zh_CN.UTF-8
一般我们会使用$LANG变量来设置Linux的字符集,一般设置为我们所在的地区,如zh_CN.UTF-8
1
2
[root@server ~]# echo $LANG
en_US.UTF-8
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
➜ ~ locale
LANG=C.UTF-8
LANGUAGE=
LC_CTYPE="C.UTF-8"
LC_NUMERIC="C.UTF-8"
LC_TIME="C.UTF-8"
LC_COLLATE="C.UTF-8"
LC_MONETARY="C.UTF-8"
LC_MESSAGES="C.UTF-8"
LC_PAPER="C.UTF-8"
LC_NAME="C.UTF-8"
LC_ADDRESS="C.UTF-8"
LC_TELEPHONE="C.UTF-8"
LC_MEASUREMENT="C.UTF-8"
LC_IDENTIFICATION="C.UTF-8"
LC_ALL=
➜ ~ echo $LANG
C.UTF-8
为了让系统能正确执行shell语句(由于自定义修改的不同语言环境,对一些特殊符号的处理区别,如中文输入法,英文输入法下的标点符号等,导致Shell无法执行),我们会使用如下语句,恢复Linux的所有的本地化设置,恢复系统到初始化的语言环境。
1
[root@server ~]# export LC_ALL=C
通配符和正则的区别
从语法上就记住,只有awk、grep、sed才识别正则表达式符号、其他都是通配符
从用法上区分
表达式操作的是文件、目录名(属于是通配符)
表达式操作的是文件内容(正则表达式)
比如如下符号区别
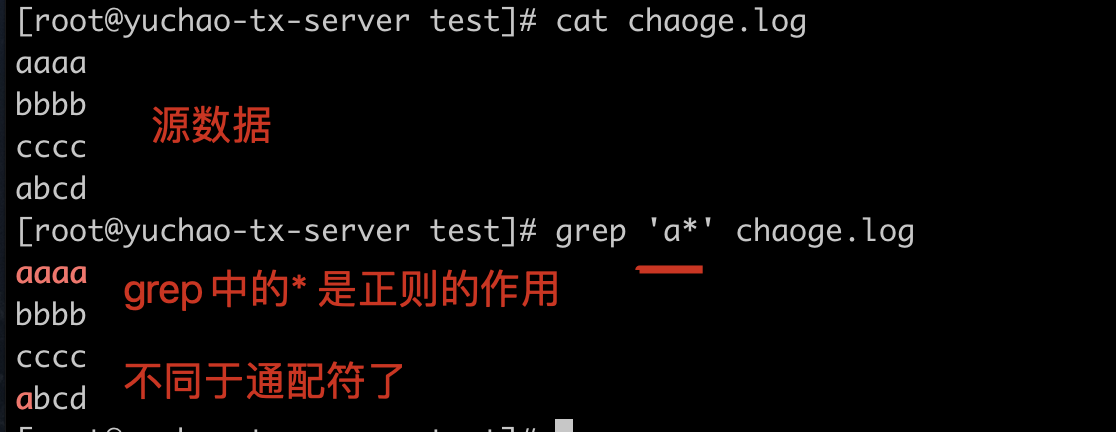
通配符和正则表达式 都有
*、?、[abcd]符号;- 通配符中,都是用来标识任意的字符, 如 ls *.log,可以找到a.log b.log ccc.log
正则中,都是用来表示这些符号前面的字符,出现的次数,如
1
grep 'a*'
实际案例
通配符,一般用于对文件名的处理,查找文件,如ls命令结合*,意思是匹配任意字符
1
2
[root@server test]# ls *.log
1.log 2.log 3.log 4.log 5.log
而三剑客,结合*符号,是处理文件内容,如grep此时的*作用就不一样了
1
2
3
4
5
6
7
8
9
10
➜ ~ cat example.log
aaaa
bbbb
cccc
abcd
➜ ~ grep 'a*' example.log
aaaa
bbbb
cccc
abcd
正则表达式分类
使用正则表达式的问题是、有两大类正则表达式规范、Linux不同的应用程序,会使用不同的正则表达式。
例如
- 不同的编程语言使用正则(Python, Java);
- Linux实用工具(sed、awk、grep);
- 其他软件使用正则(MySQL、Nginx);
正则表达式是通过正则表达式引擎(regular expression engine)实现的。正则表达式引擎是 一套底层软件,负责解释正则表达式模式并使用这些模式进行文本匹配。
在Linux中,有两种流行的正则表达式引擎,基于UNIX标准下的正则表达式符号规则有两类:
POSIX基础正则表达式(basic regular expression,BRE)引擎;
POSIX扩展正则表达式(extended regular expression,ERE)引擎 ;
解释POSIX
POSIX(Portable Operating System Interface)是Unix系统的一个设计标准。
当年最早的Unix,源代码流传出去了,加上早期的Unix不够完善,于是之后出现了好些独立开发的与Unix基本兼容但又不完全兼容的OS,通称Unix-like OS
两类、正则表达式符号
Linux规范将正则表达式分为了两种
基本正则表达式(BRE、basic regular expression)
BRE对应元字符有
1
^ $ . [ ] *
其他符号是普通字符
1
; \
扩展正则表达式(ERE、extended regular expression)
ERE在在BRE基础上,增加了
1
( ) { } ? + |等元字符。
转义符
反斜杠
\,反斜杠用于在元字符前添加,使其成为普通字符。
基本正则表达式(BRE)
测试文本数据
1
2
3
4
5
6
7
8
9
10
11
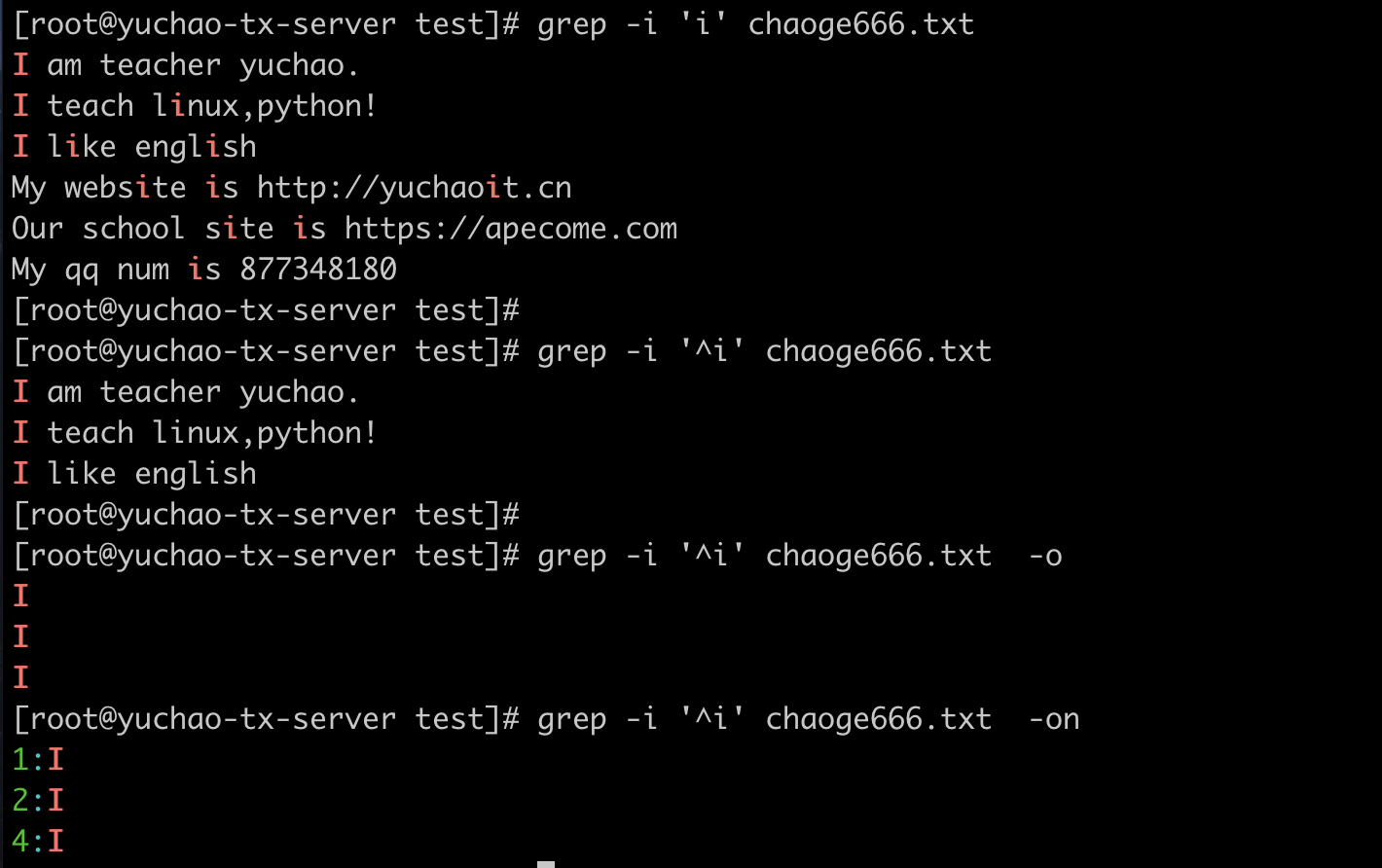
[root@server test]# cat chaoge666.txt
I am teacher yuchao.
I teach linux,python!
I like english
My website is http://yuchaoit.cn
Our school site is https://apecome.com
My qq num is 877348180
Good good study , day day up!
关于单引号、双引号
- 正则的模式,建议使用双引号
- 如果未涉及变量等,用单引号也不影响
grep与正则
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
GREP(1) User Commands GREP(1)
NAME
grep, egrep, fgrep, rgrep - print lines that match patterns
SYNOPSIS
grep [OPTION...] PATTERNS [FILE...]
grep [OPTION...] -e PATTERNS ... [FILE...]
grep [OPTION...] -f PATTERN_FILE ... [FILE...]
DESCRIPTION
grep searches for PATTERNS in each FILE. PATTERNS is one or more patterns separated by newline characters, and grep
prints each line that matches a pattern. Typically PATTERNS should be quoted when grep is used in a shell command.
A FILE of “-” stands for standard input. If no FILE is given, recursive searches examine the working directory, and
nonrecursive searches read standard input.
Debian also includes the variant programs egrep, fgrep and rgrep. These programs are the same as grep -E, grep -F,
and grep -r, respectively. These variants are deprecated upstream, but Debian provides for backward compatibility.
For portability reasons, it is recommended to avoid the variant programs, and use grep with the related option
instead.
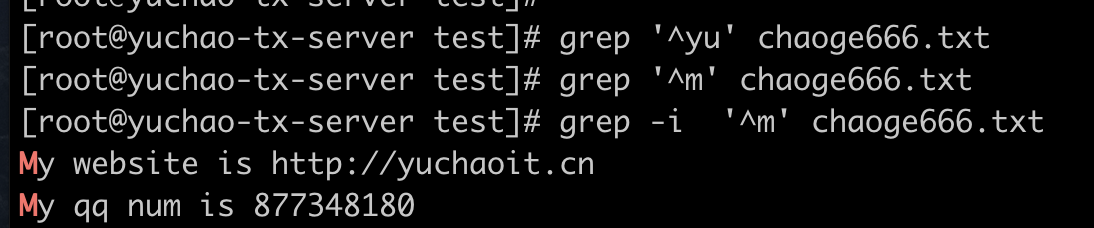
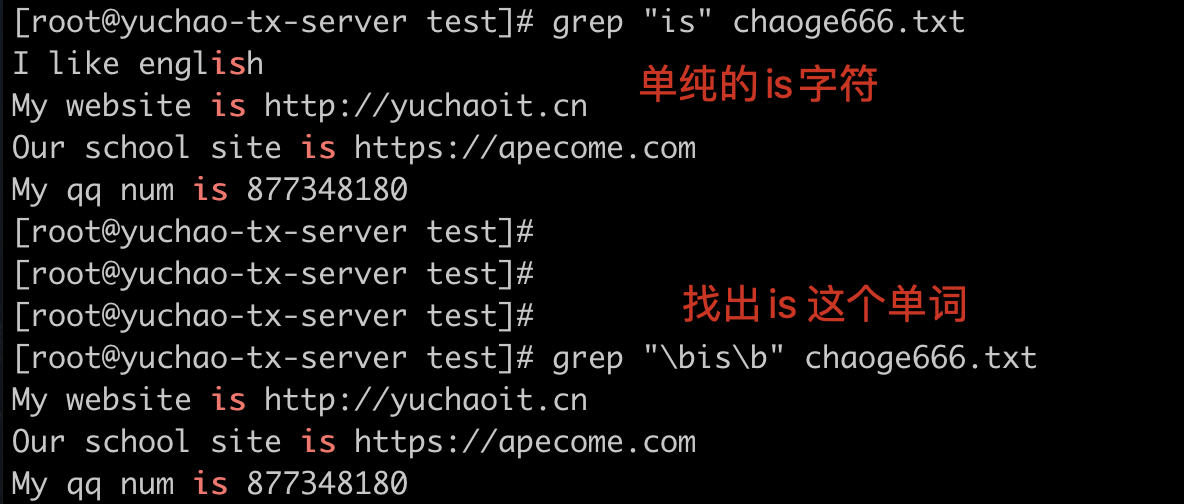
例如传入的pattern(模式) ,我们可以统称你写的正则是模式,比如^m,是以m开头的行;
1
2
3
[root@server test]# grep -i -n '^m' chaoge666.txt
6:My website is http://yuchaoit.cn
8:My qq num is 877348180
^ 尖角符
语法:写于最左侧,如^yu 逐行匹配,找到以yu开头的内容
结合grep用法,-i 忽略大小写
结合grep的参数 -o 只显示一行中匹配出来内容
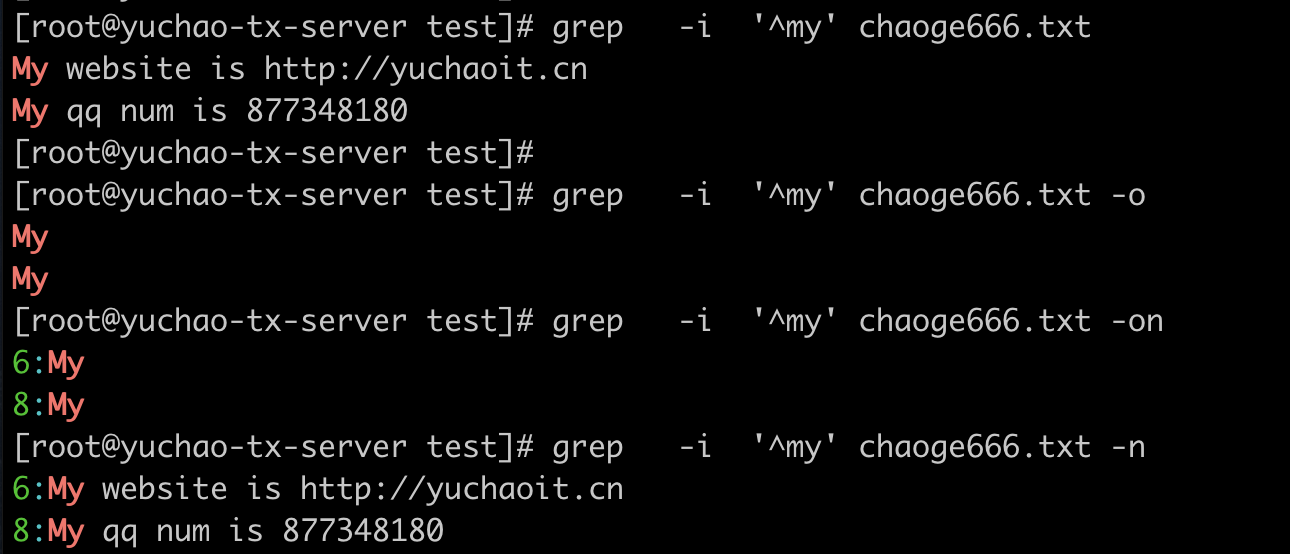
结合grep,过滤出以i开头的行,且显示行号
$ 美元符
1
2
3
语法
word$ 匹配以word结尾的行
匹配所有以字符n结尾的行

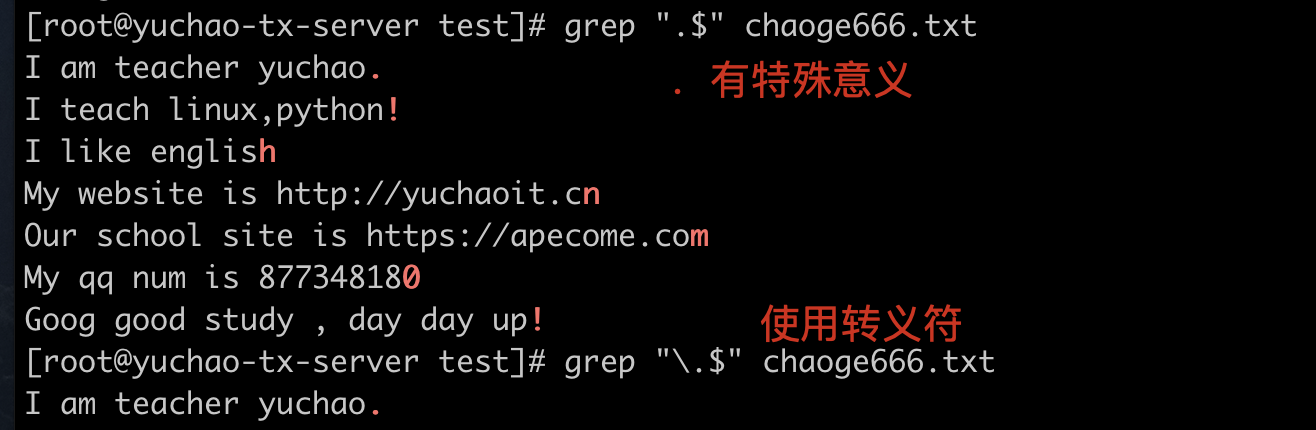
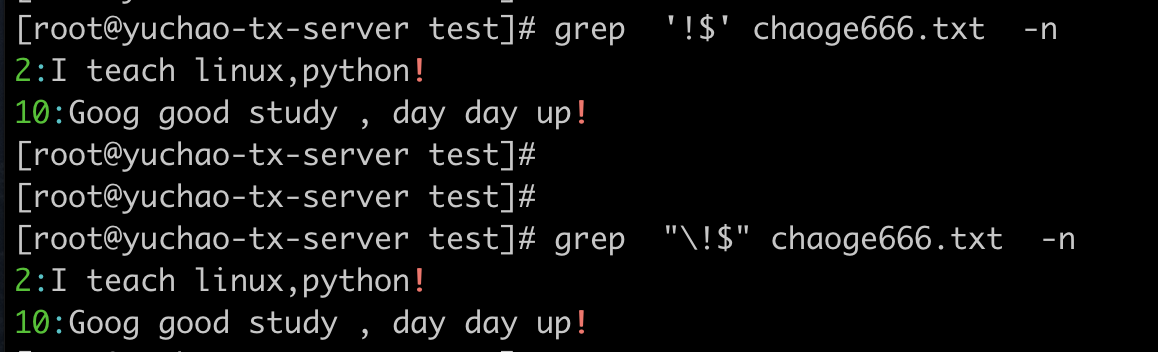
匹配所有以小数点. 结尾的行,这里因为.也有特殊作用,因此得使用单引号、或者转义符。
单、双引号区别
单引号、所见即所得,可以用于匹配如标点符号,还原其本义。

双引号、能够识别linux的特殊符号、或变量,需要借助转义符还原字符本义。
当需要引号嵌套时,一般做法是,双引号,嵌套单引号。
^$ 匹配空行
找出文件的空行

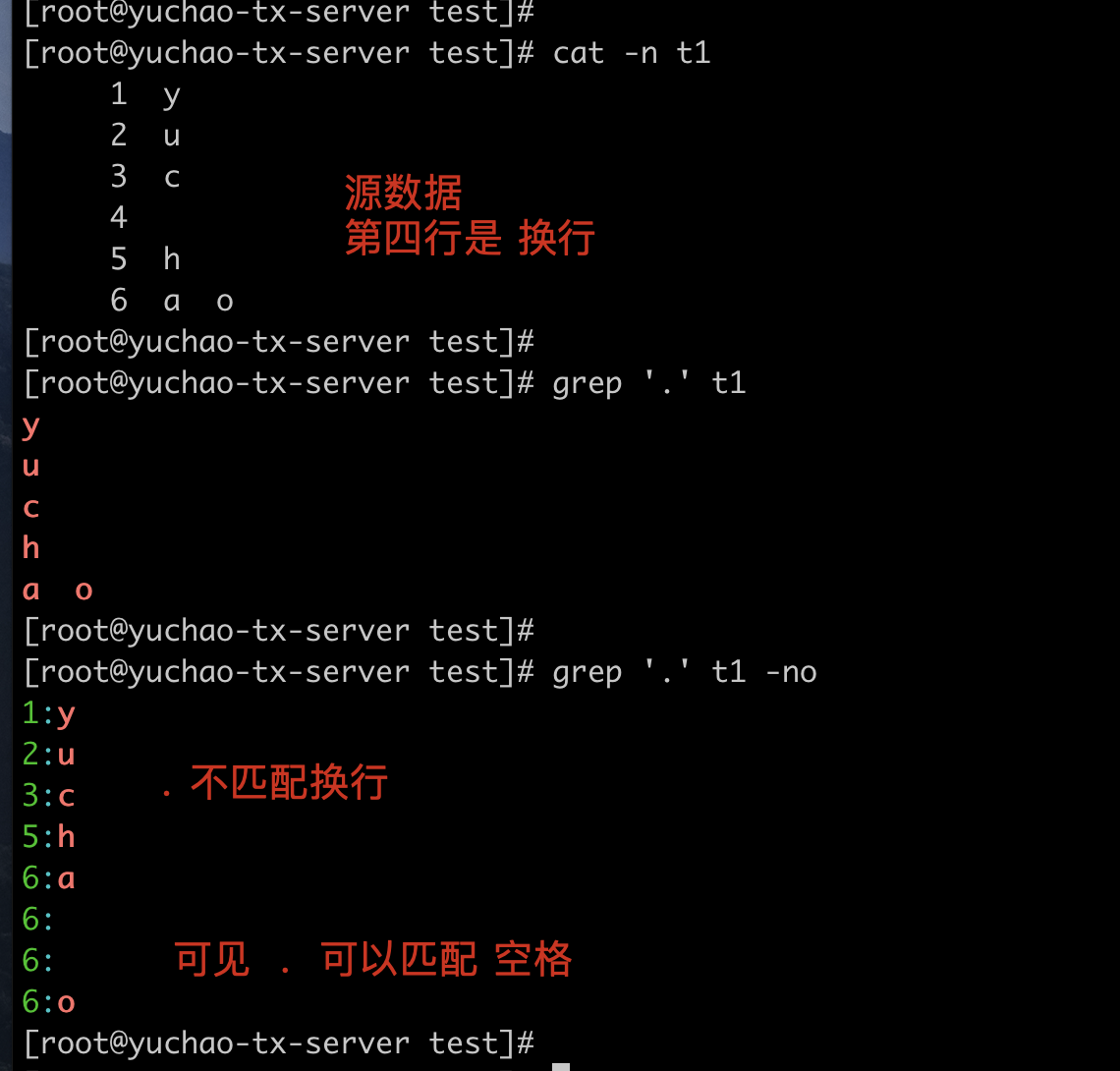
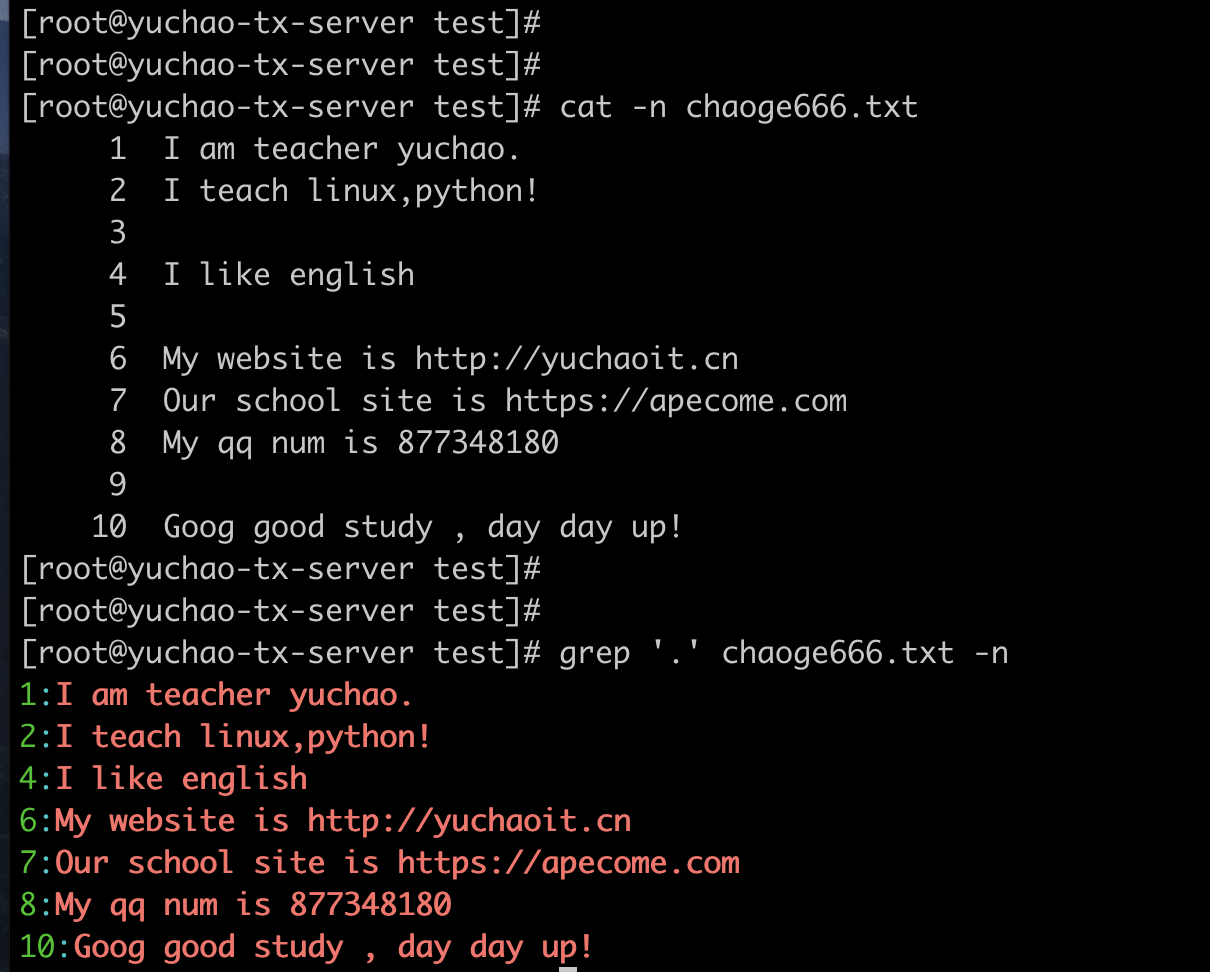
. 点符
. 匹配除了换行符以外所有的内容、字符+空格,除了换行符。
. 点处理空格、换行
. 可以匹配到空格,以及任意字符
但是点,不匹配换行符。
. 匹配除换行符的所有字符
. 代表任意一个字符
分别传入grep的模式
1
2
3
y.
y.. 任意2个字符
实践代码
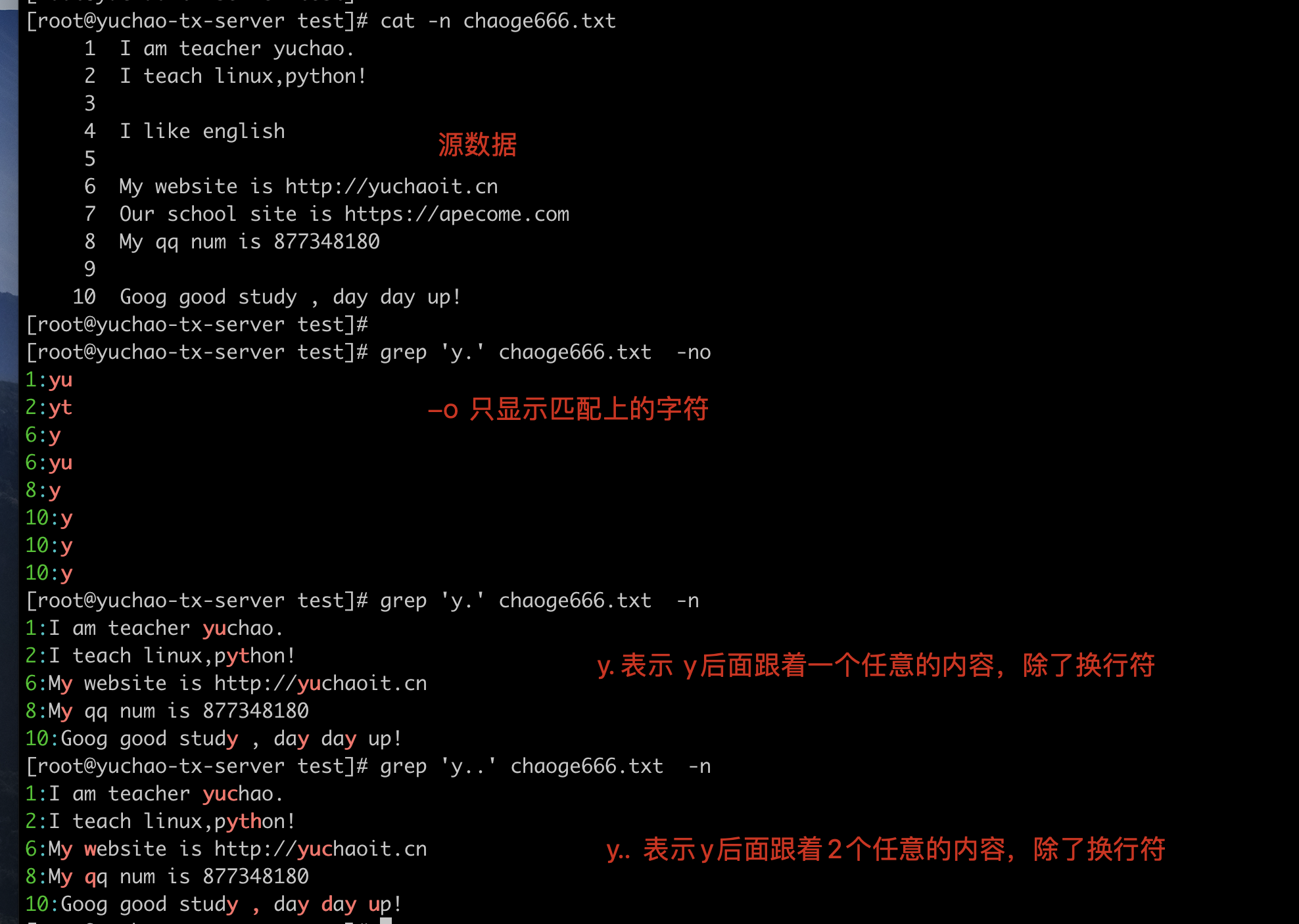
匹配符合模式.ac 的行

.$ 匹配任意字符结尾
拿到每一行的结尾
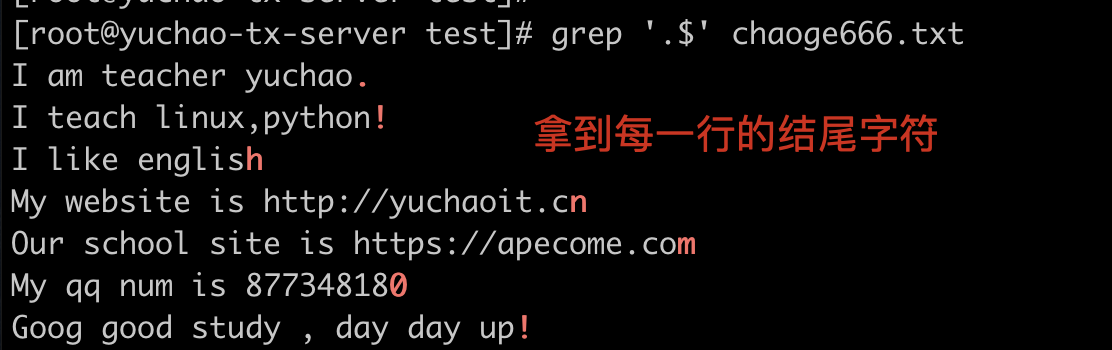
. 和转义符
只想拿到每一行结尾的普通小数点 .,需要对点转义

\ 转义符
转义字符,让有特殊意义的字符,现出原形,还原其本义。
1
2
如
\. 还原为小数点
空格、换行、tab
https://deerchao.cn/tools/wegester/使用这个网址来测试换行符的匹配
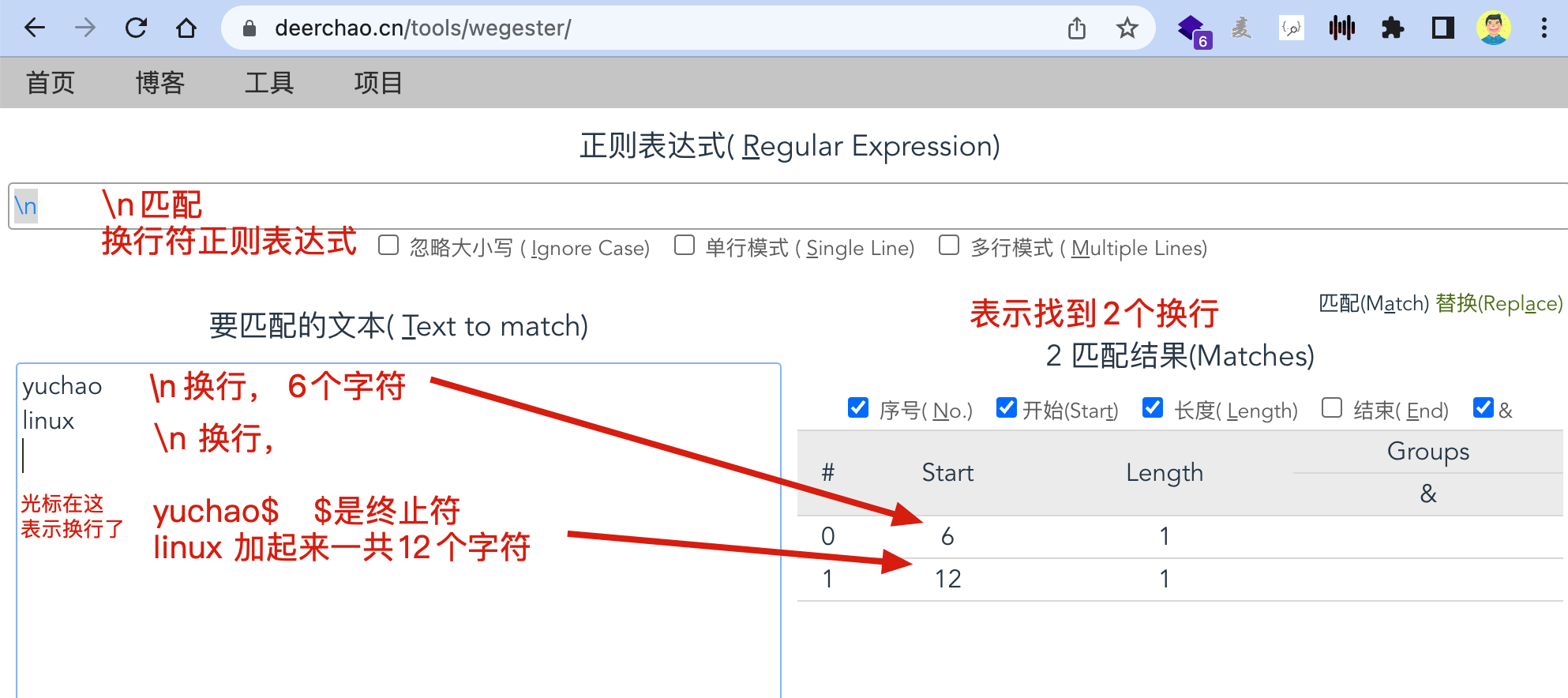
关于Linux的换行符

语法记忆
1
2
3
4
5
6
7
8
9
10
11
\b 匹配单词边界,如我想从字符串中“This is Regex”匹配单独的单词 “is” 正则就要写成 “\bis\b”
\n 匹配换行符 ,表示newline,向下移动一行,不会左右移动
\r 匹配回车符,表示return,回到当前行的最左边
Linux换行符是\n,表示\r+\n 换行且回车,换行且回到下一行的行首
Windows换行符是\r\n,表示回车+换行
\t 匹配一个横向的制表符,等于tab键
* 星号
重复前一个字符0此或n次
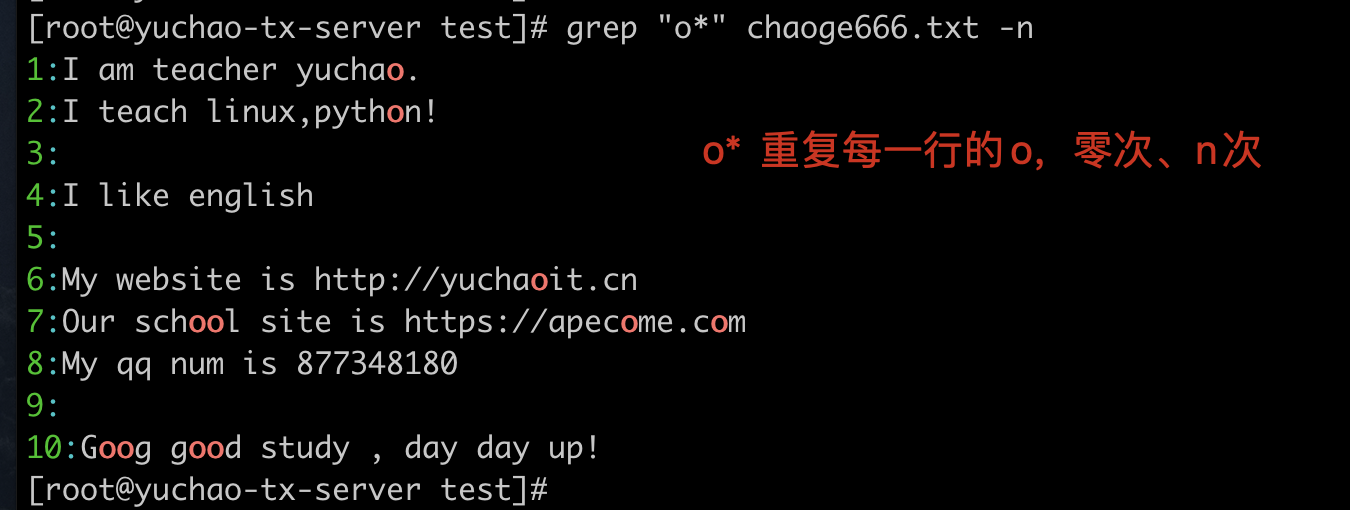
.* 符
匹配任意字符
1
2
3
4
5
.表示任意一个字符,*表示匹配前一个字符0次或多次
因此放一起,代表匹配每一行所有内容,包括空格
注意 . 点不匹配换行
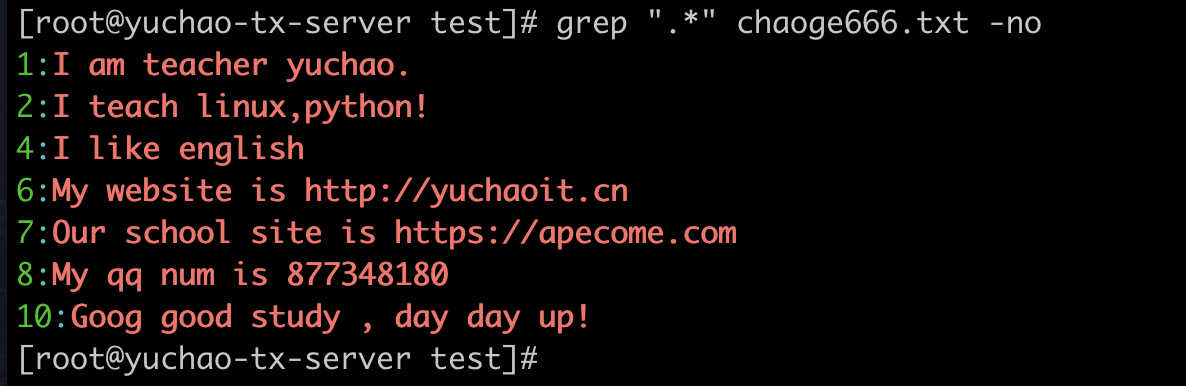
图解点 . 不匹配换行
1
2
首先,不匹配换行这事,是因为 . 的作用
.* 是重复前面这个字符0次或N次
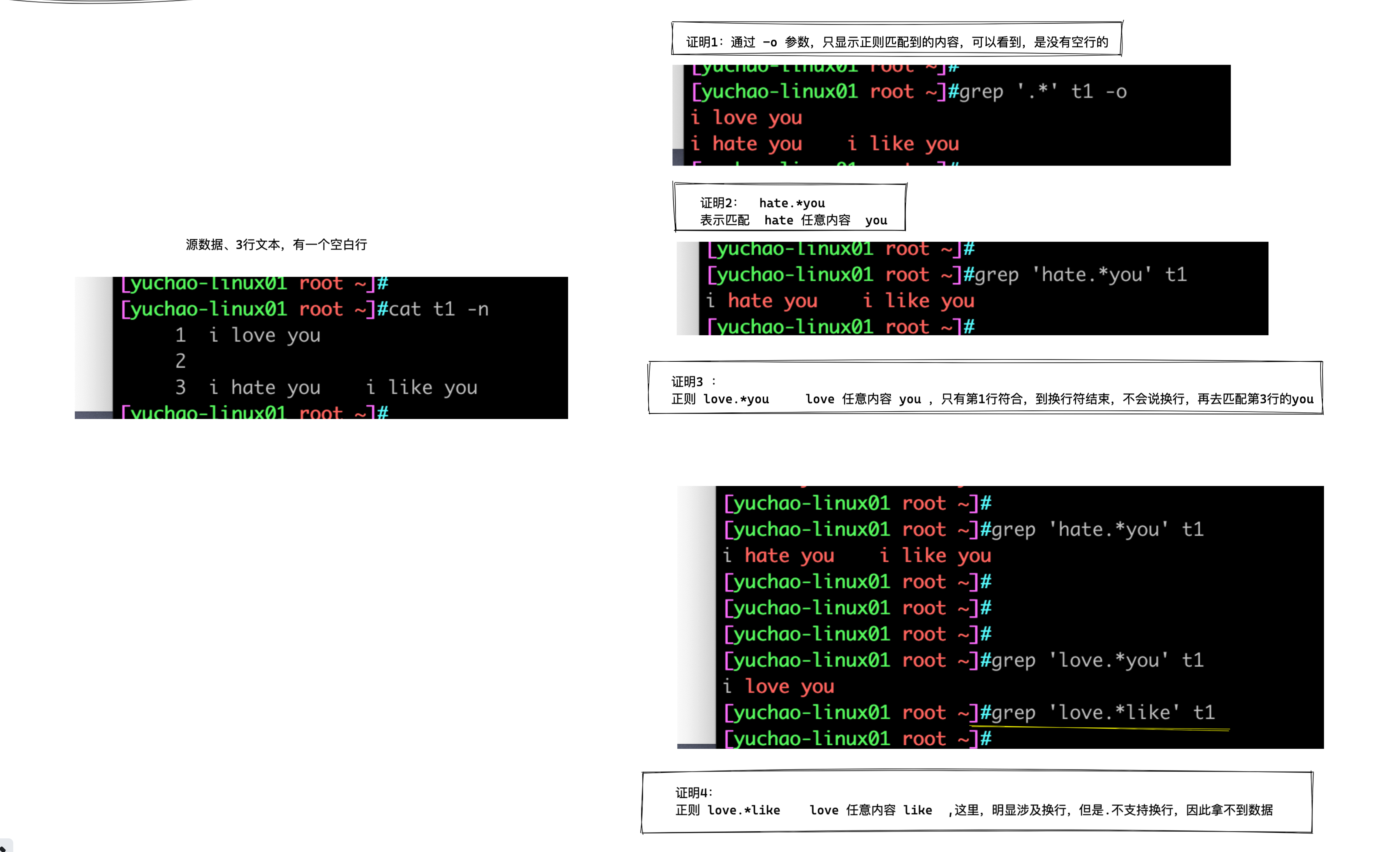
^.* 符
1
2
语法
^.* 表示以任意多个字符开头的行
基础用法,^.*
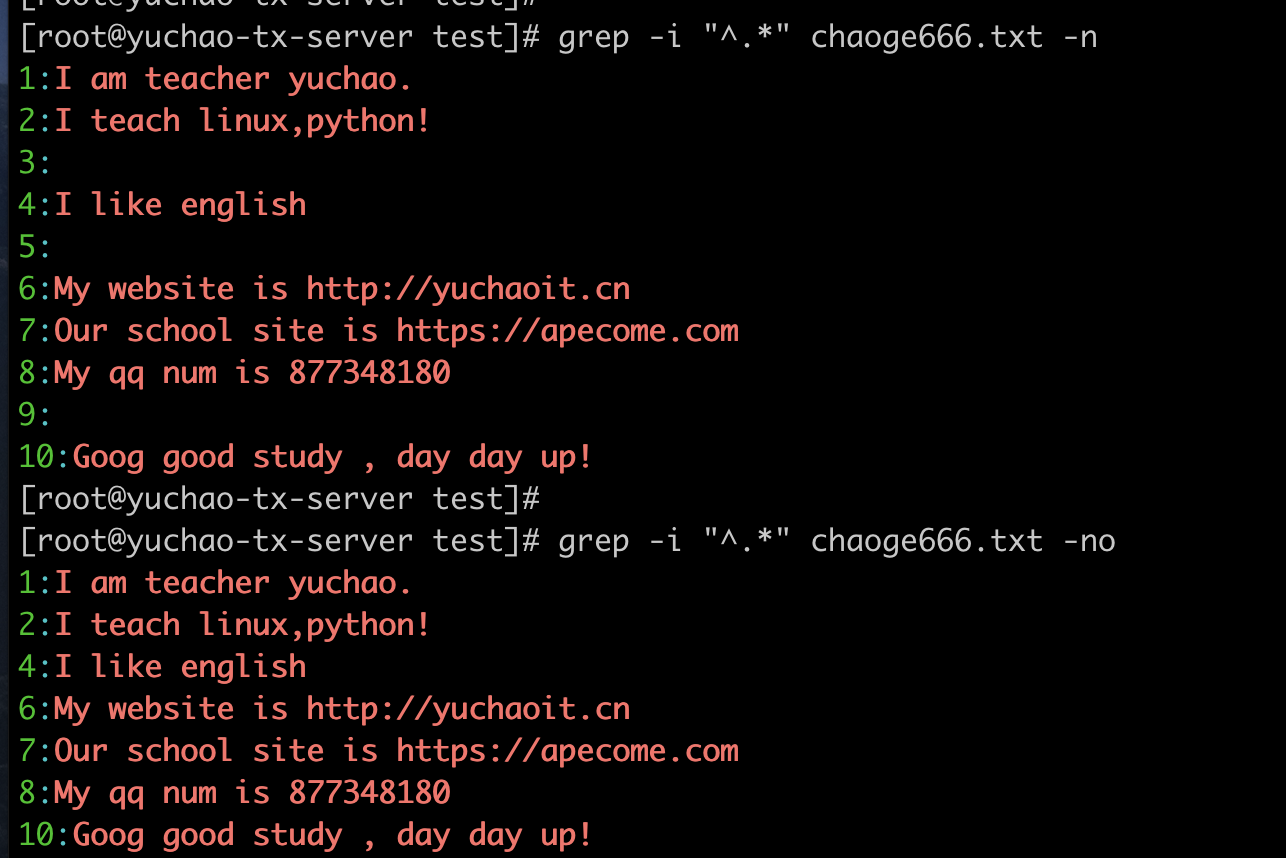
找出任意以字母i开头的行,且匹配后续所有内容

加大难度
找出任意以字母i开头的行,且以h结尾的行

.*$ 符
以任意多个字符结尾的行
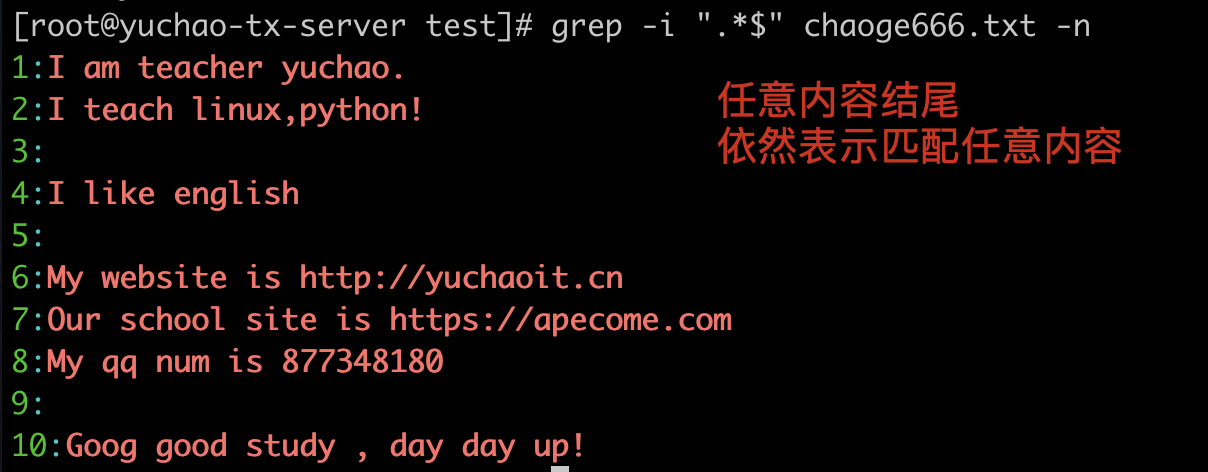
你可以加上条件,例如p.*$
1
2
以p.*$结尾的行
等于、匹配出从p到结尾的所有内容

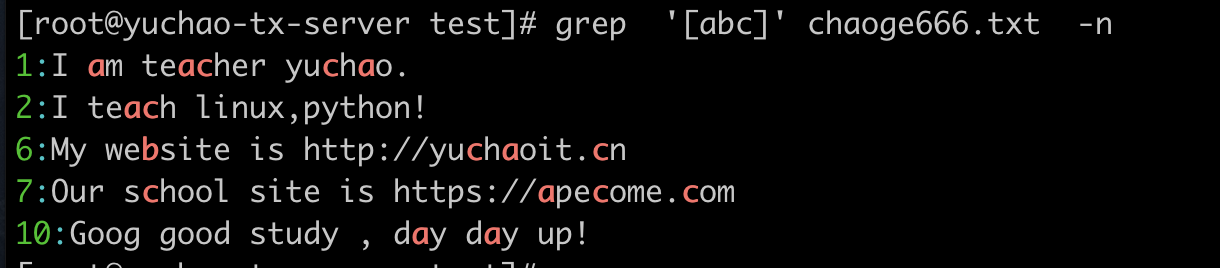
[ ] 中括号
中括号,有如下用法
[abc]
1
[abc] 匹配括号内的小写a、b、c字符
关于到大小写的精准匹配,就别添加忽略大小写参数了
[a-z]、 [A-Z] 、[a-zA-z]、[0-9]
1
2
3
4
5
[a-z] 匹配所有小写单个字母
[A-Z] 匹配所有单个大写字母
[a-zA-Z] 匹配所有的单个大小写字母
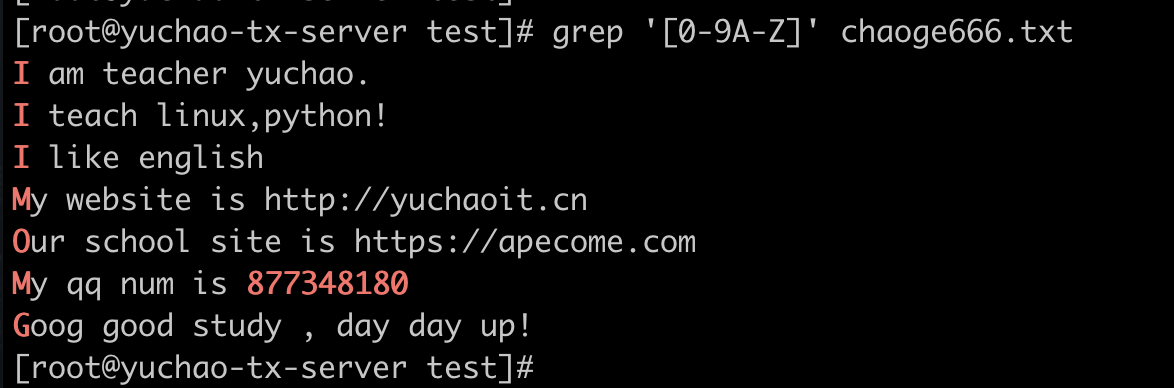
[0-9] 匹配所有单个数字
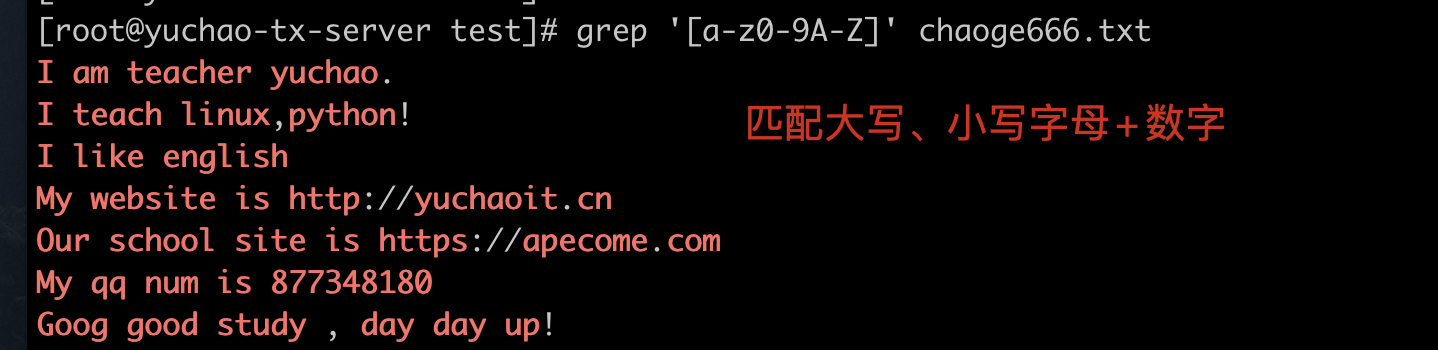
[a-zA-Z0-9] 匹配所有数字和字母
[a-z] 匹配小写字母
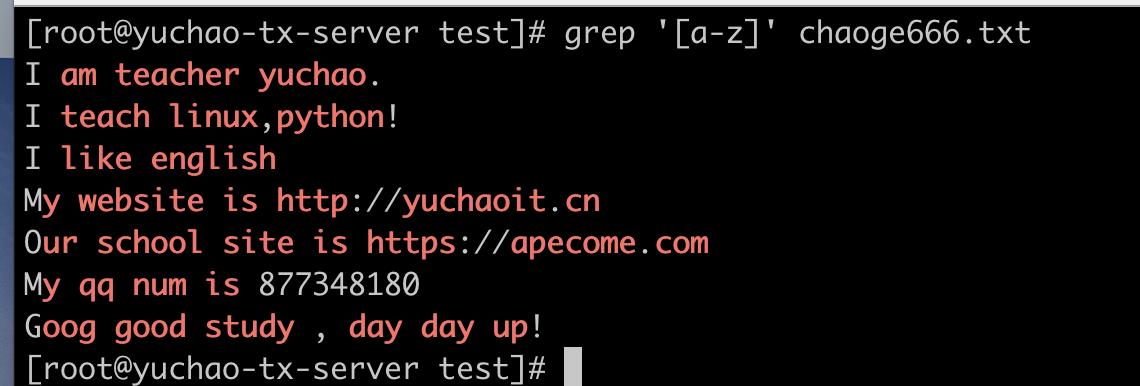
[A-Z] 匹配大写字母
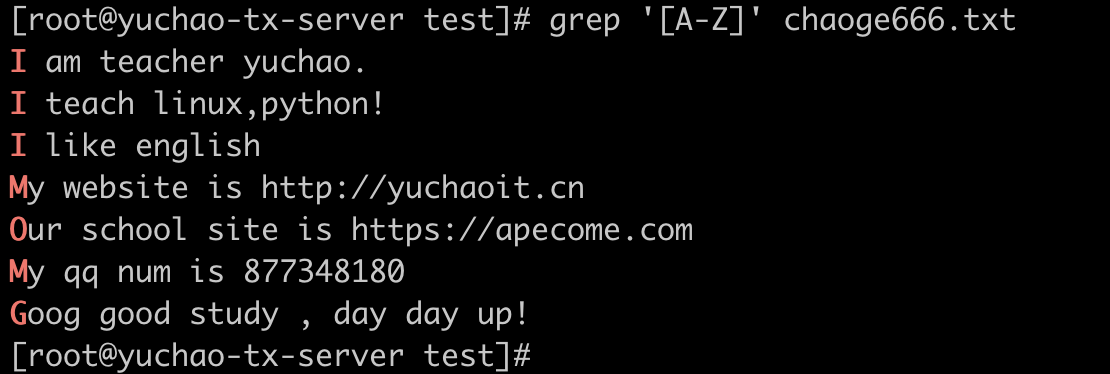
[a-z0-9] 匹配小写字母和数字
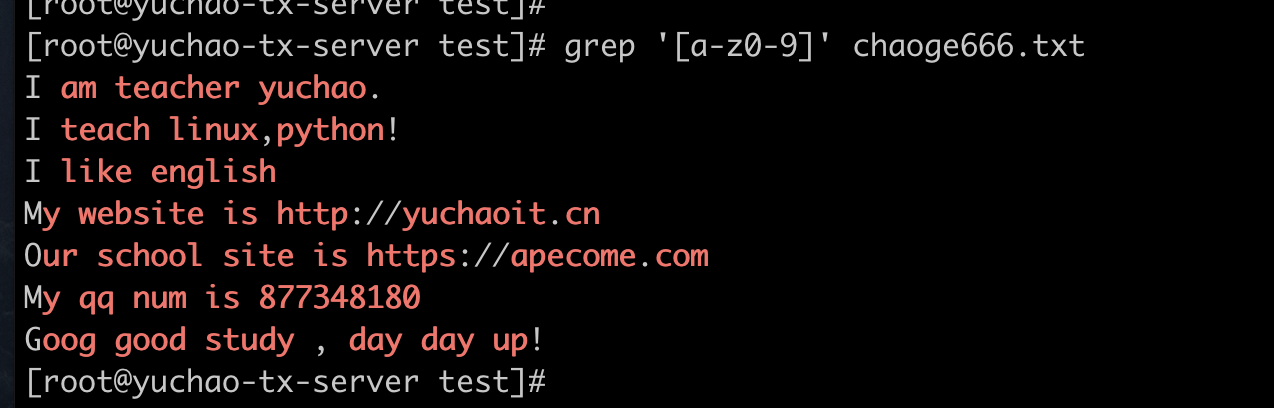
[0-9A-Z] 匹配大写字母和数字
[a-z0-9A-Z] 匹配大写、小写字母、数字
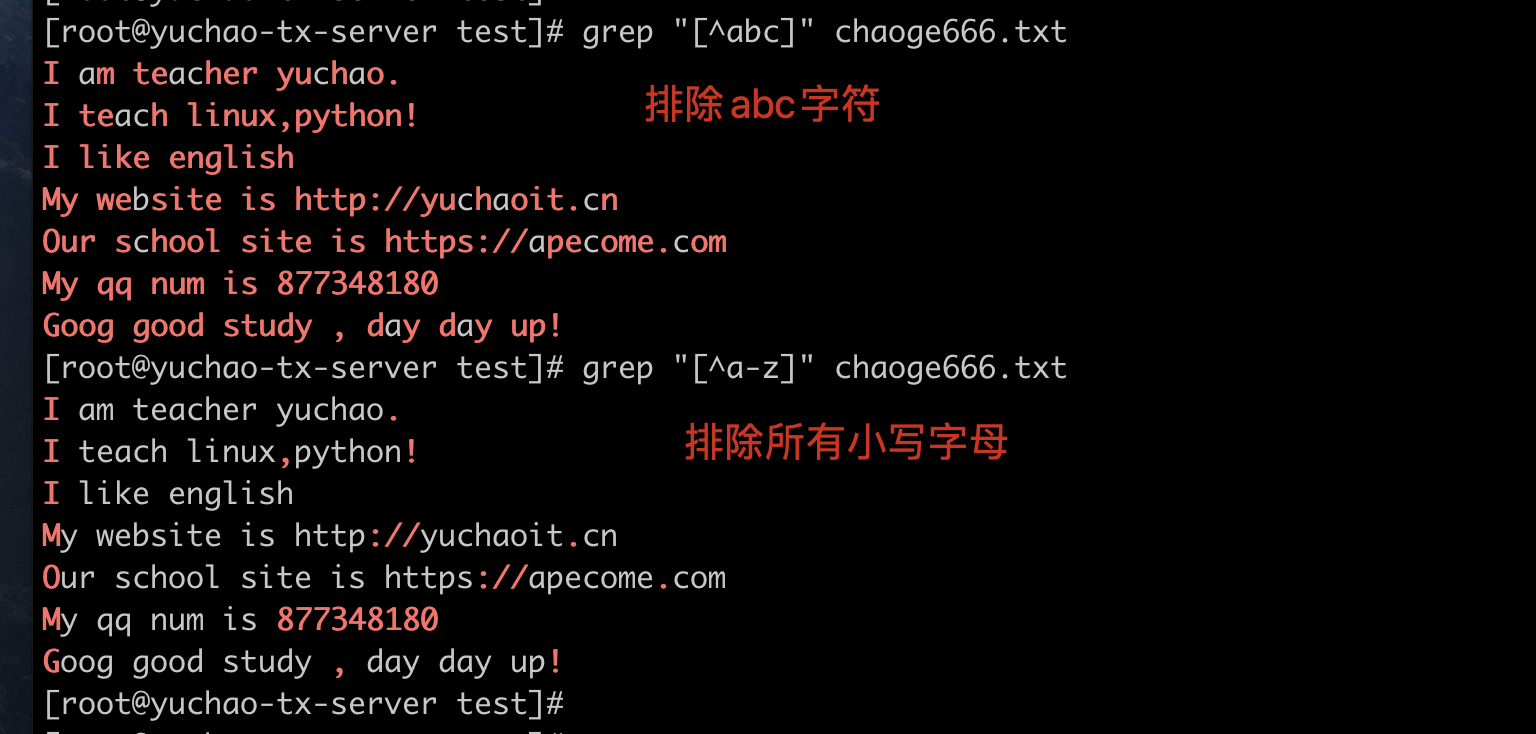
[^abc]中括号取反
1
2
3
4
5
语法
[^abc] 排除中括号里的a、b、c ,和单独的^符号,作用是不同的
[^a-z] 排除小写字母
{ } 花括号(扩展正则)
a\{n,m\}
1
2
3
a\{n,m\} 重复字符a,n到m次
a\{1,3\} 重复字符a,1到3次
实践
1
2
3
4
5
6
7
8
9
10
11
12
13
14
测试数据
[root@server test]# cat chaoge666.txt
I am teacher yuchao.
I teach linux,python!
I like english
My website is http://yuchaoit.cn
Our school site is https://apecome.com
My qq num is 877348180
my qq num is not 87777773333344444888811188880000
Goog good study , day day up!
正则
1
2
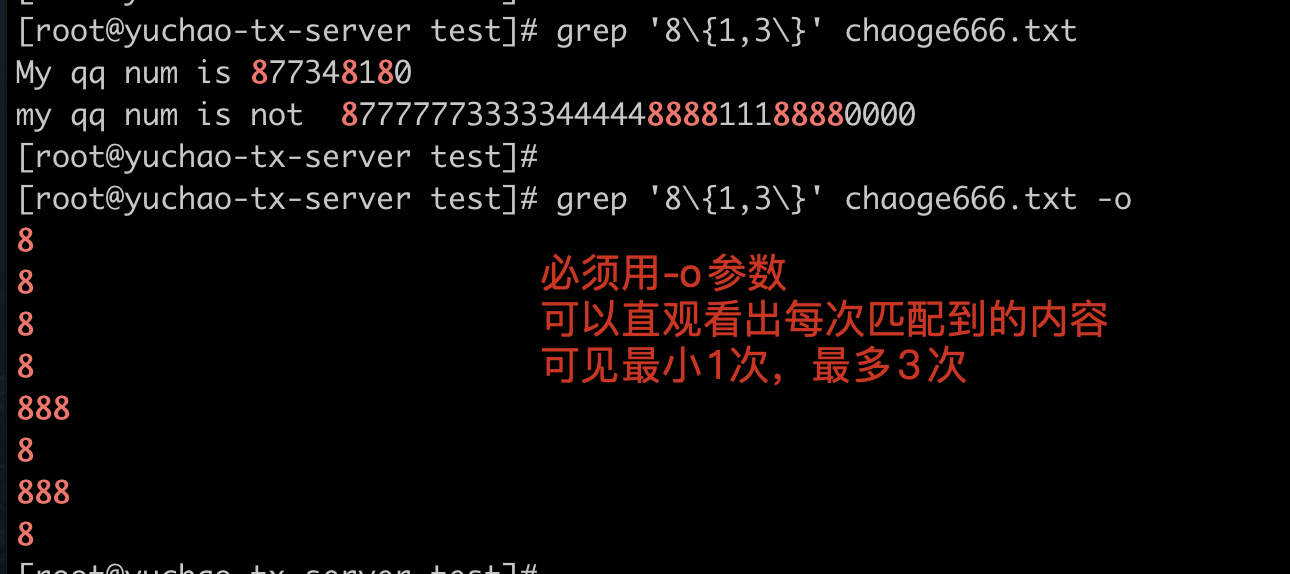
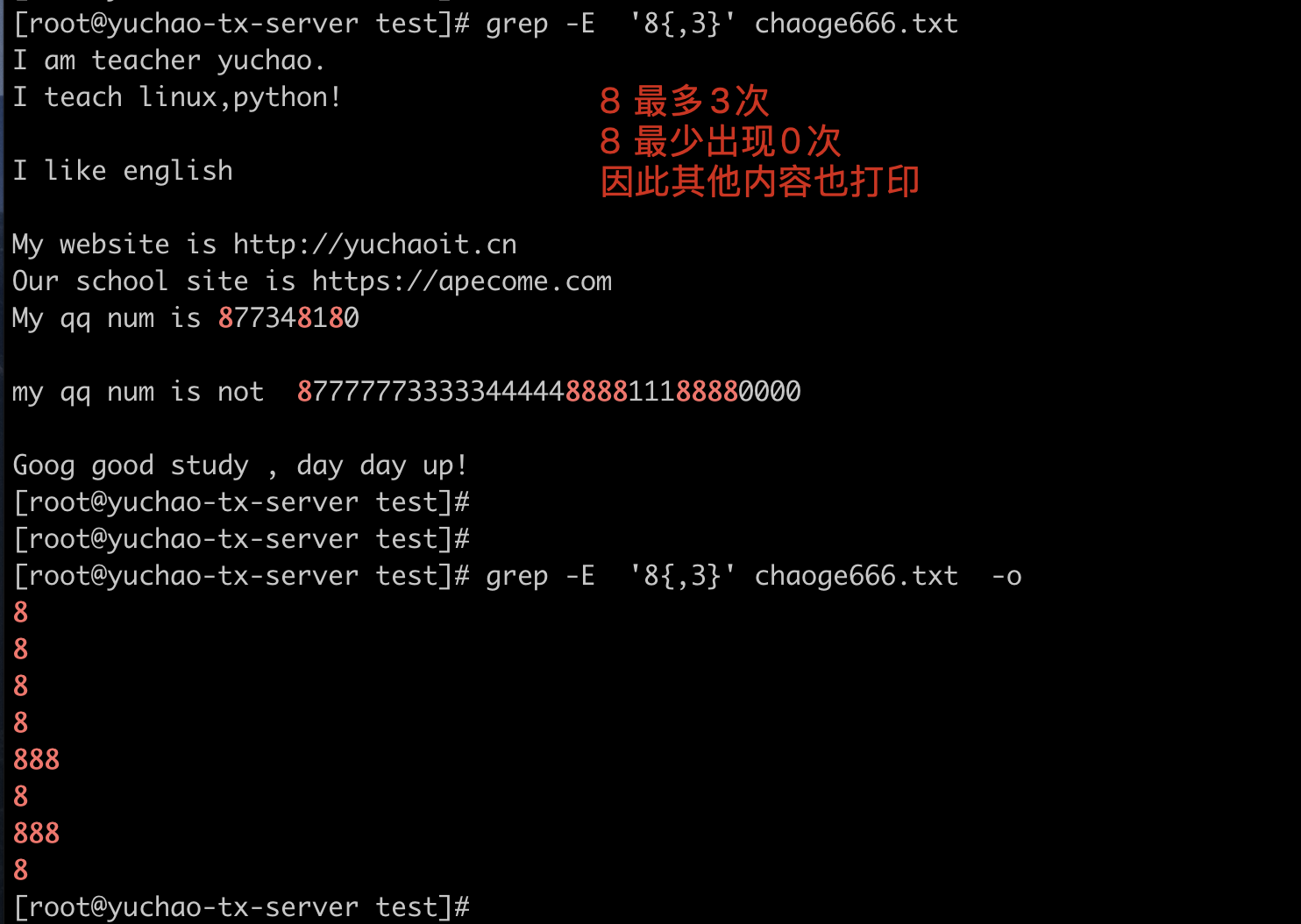
8\{1,3\}
匹配数字8一次到3次
1
2
3
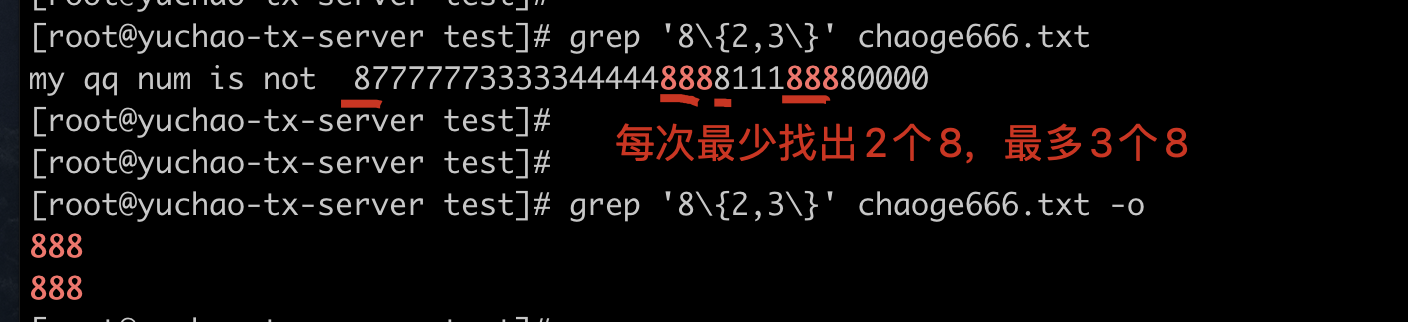
每次最少找出2个8、最多3个8
8\{2,3\}
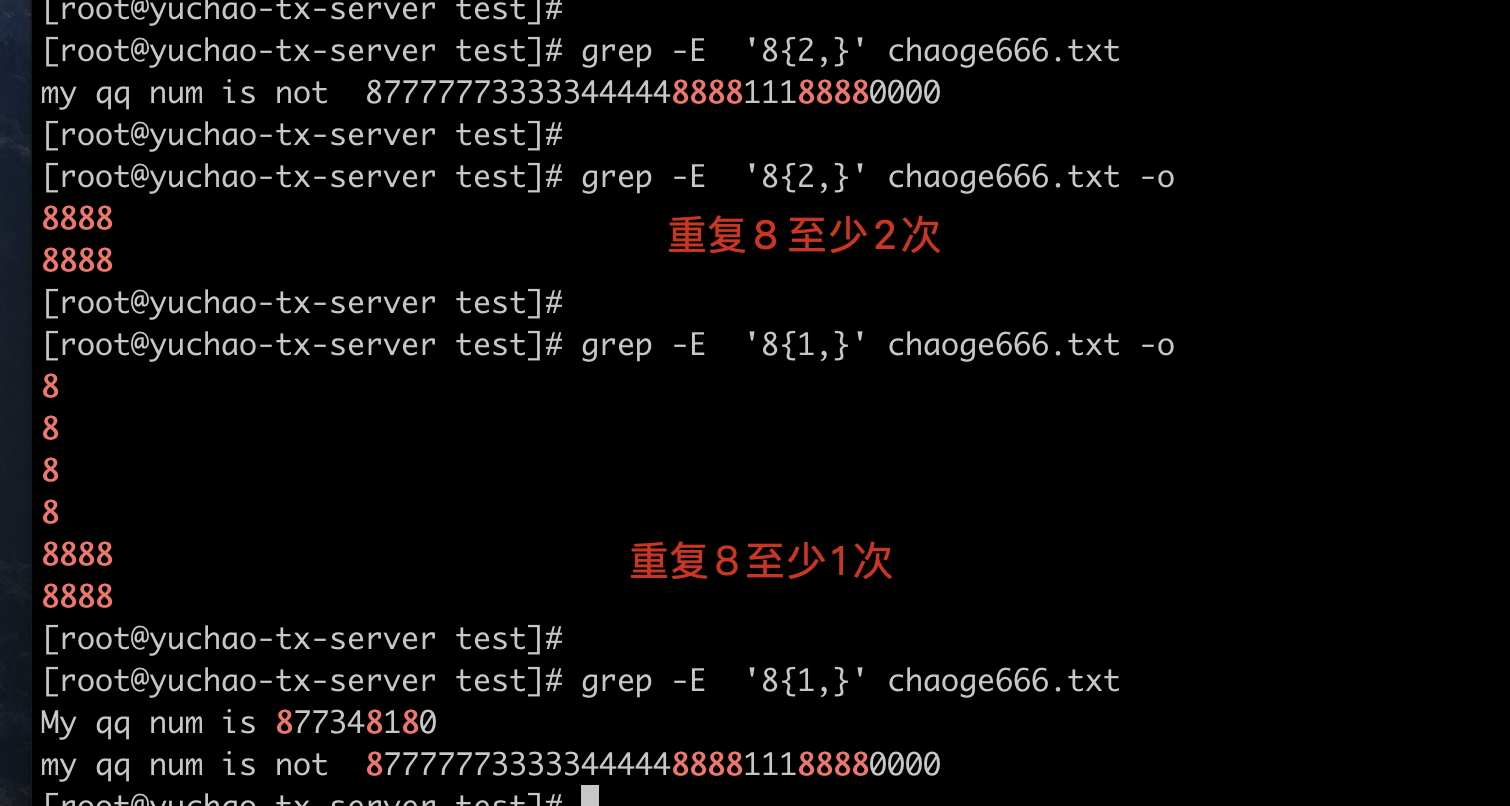
grep 默认不认识扩展正则 {}
grep默认不认识扩展正则{},识别不到它的特殊作用,因此只能用转义符,让他成为有意义的字符。

1
2
3
4
5
6
办法1
使用转义符 \{\}
办法2,让grep认识花括号,可以省去转义符
使用egrep命令
或者 grep -E
实践

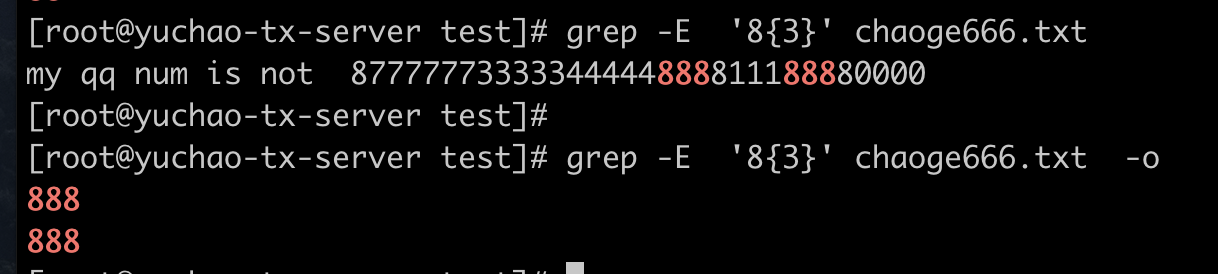
a\{n,\}
重复a字符至少n次,可以用简写了
a\{n\}
重复字符a,正好n次。
a\{,m\}
匹配字符a最多m次。
扩展正则表达式(ERE)
这样记忆就好
- 基本正则表达式
- 属于早期正则表达式,支持一些基本的功能
- 与grep、sed命令结合使用
- 扩展正则表达式
- 后来添加的正则表达式
- 和egrep、awk命令结合
+ 加号
1
2
3
4
5
语法
+
重复前一个字符1次或多次
注意和*的区别,*是0次或多次
匹配一次或者多次0,没有0的行是不会显示的
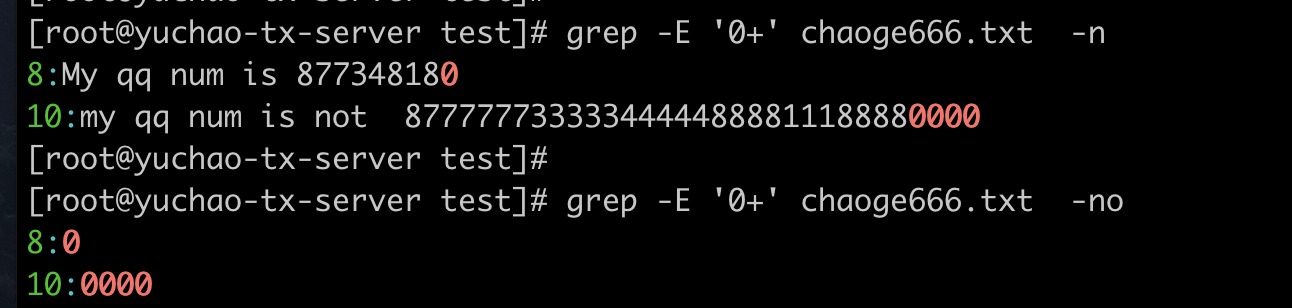
0+
找出一个、或者多个数字零
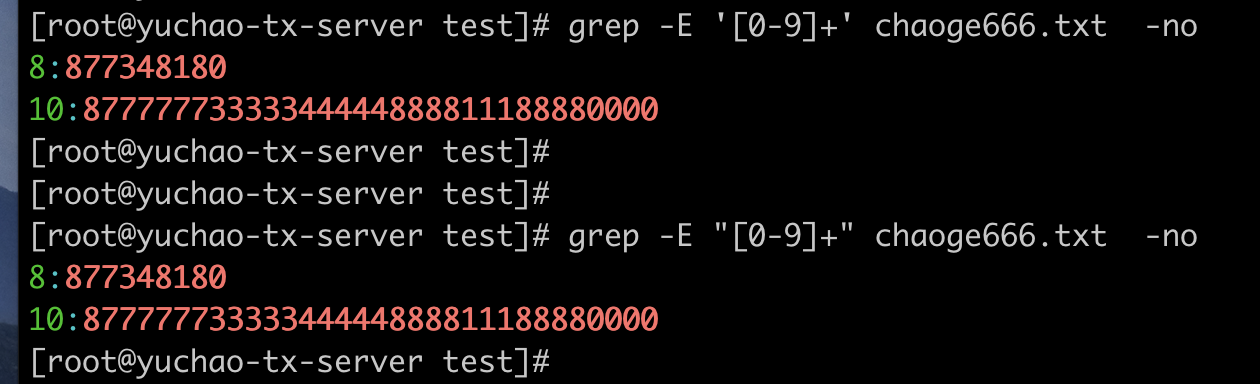
[0-9]+
从文中找出连续的数字,排除字母,特殊符号、空格
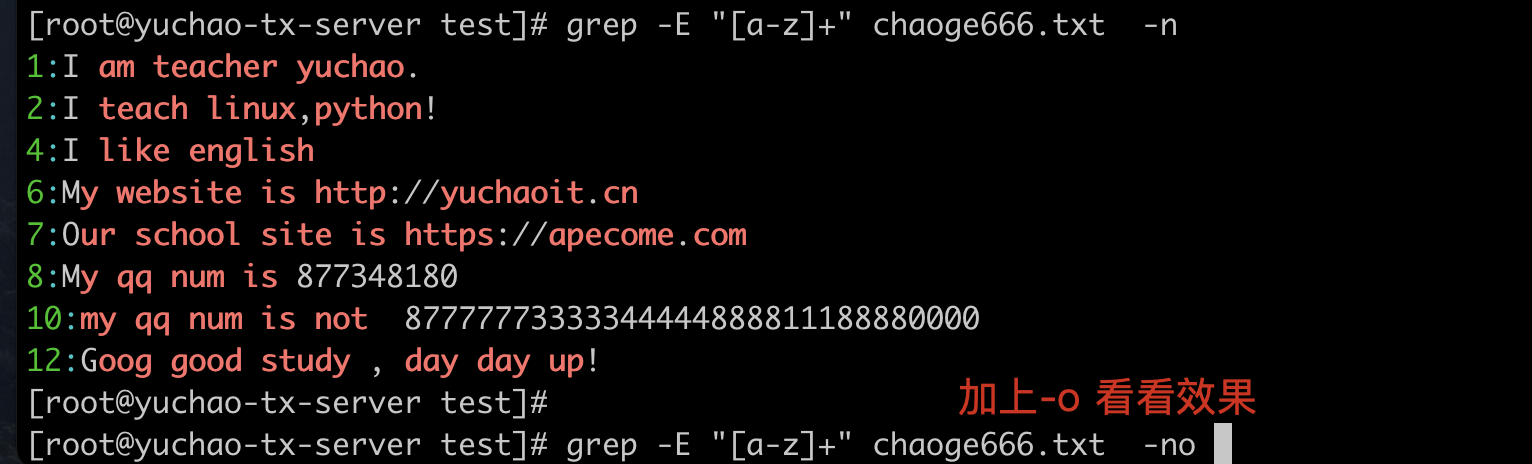
[a-z]+
找出连续的小写字母、排除大写字母、标点符号、数字
[A-Za-z0-9]+
注意,这里添加了+号,就是找的连续的字母数字了、缺少+号则是每次匹配单个字符
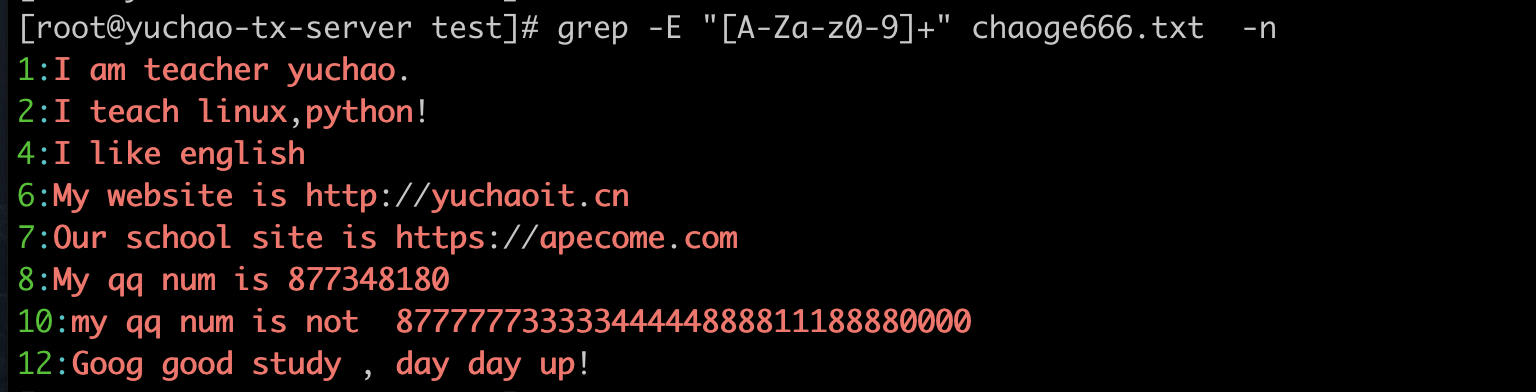
[^A-Za-z0-9]+]
此写法,找出除了数字、大小写字母以外的内容,如空格、标点符号。
你可以使用-o参数,看到每次匹配的内容。
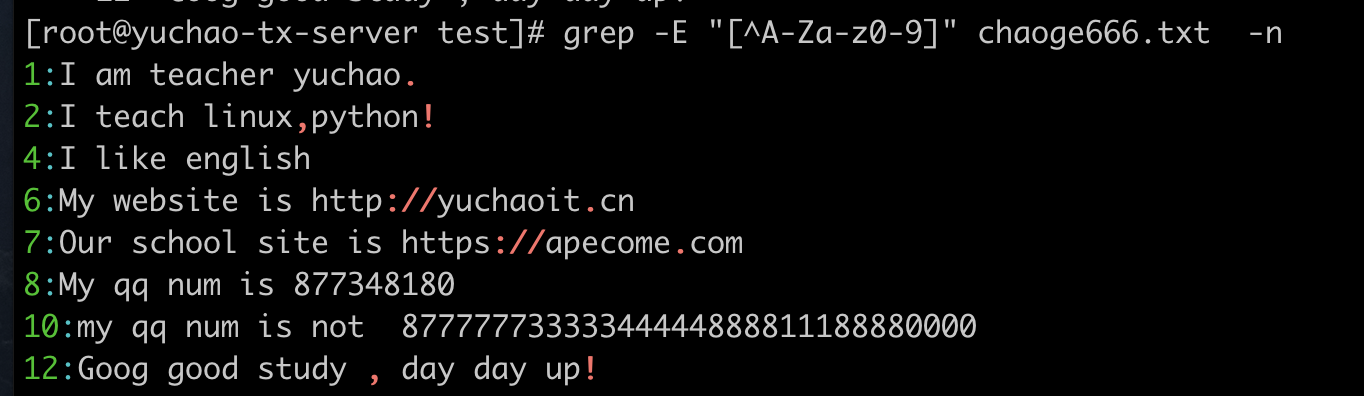
*和+的区别
1
2
3
4
语法
*是重复0次、重复多次,因此没匹配到的行也过滤出来了
+是重复1次、多次、因此至少匹配到1次才看到
例如,我们来找到字母o,看如下2个写法
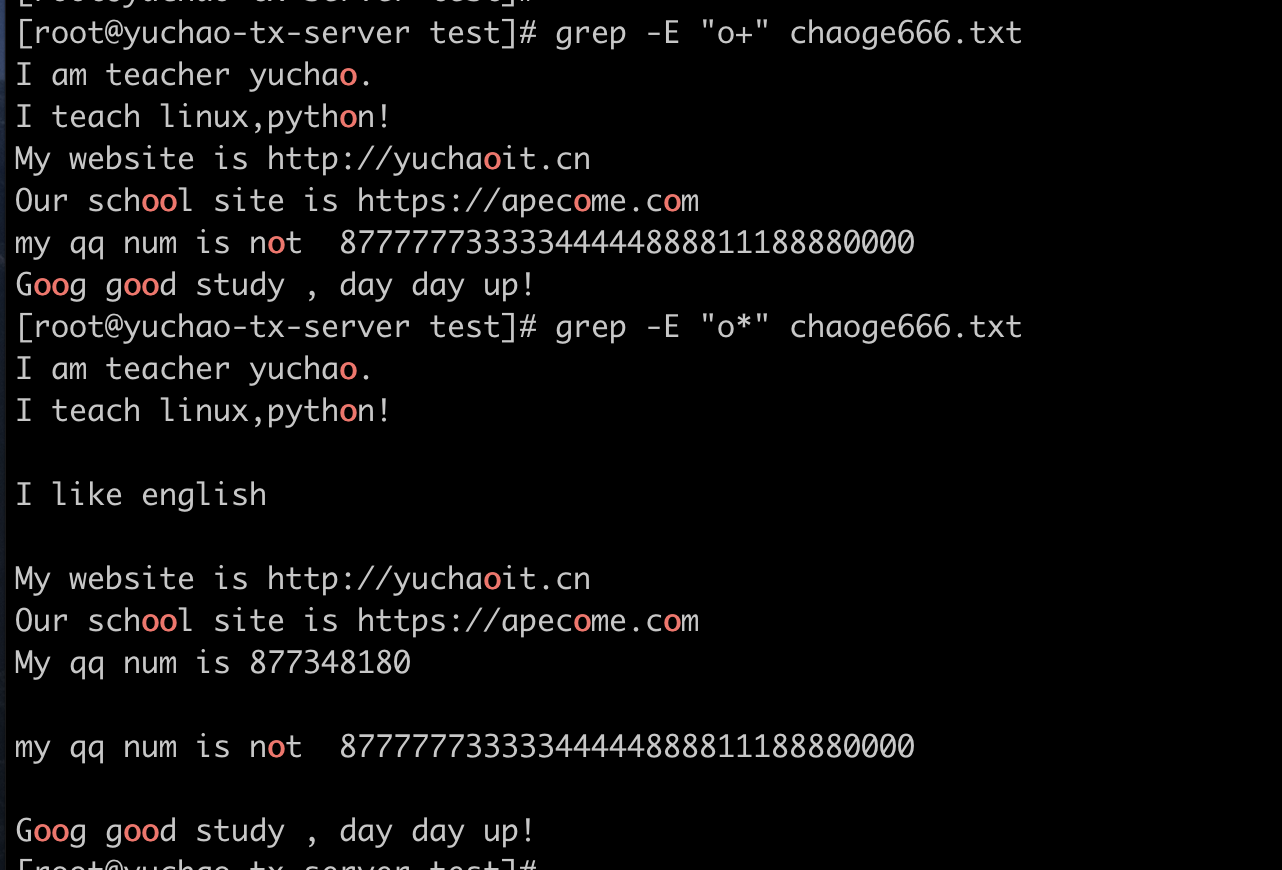
go*d和go+d和go?d区别
准备测试数据
1
2
[root@server test]# cat god.log
I am God, I need you to good good study and day day up, otherwise I will send you to see Gd,oh sorry, gooooooooood!
关于寻找god、goooood、gd的区别
1
2
3
4
5
6
7
8
go*d 可以有0个或者n个字母o
go*d 可以找到god、good、gd、gooooooooood
go+d 可以有一个或n个字母o
go+d 可以找到god、good、gooooooooood
go?d 可以有0个或者1个字母0
go?d 可以找到gd、god

| 或者符
竖线在正则里是或者的意思
查看内存信息

查看文件系统inode和block信息
ext4文件系统
1
2
3
4
5
6
7
8
9
[242-yuchao-class01 root ~]#dumpe2fs /dev/sdc |grep -Ei '^(inode|block)'
dumpe2fs 1.42.9 (28-Dec-2013)
Inode count: 1310720
Block count: 5242880
Block size: 4096
Blocks per group: 32768
Inodes per group: 8192
Inode blocks per group: 512
Inode size: 256
xfs文件系统
1
2
3
[242-yuchao-class01 root /mnt]#xfs_info /mnt |grep -E 'blocks.*imax.*|isize='
meta-data=/dev/sdd isize=512 agcount=4, agsize=3276800 blks
data = bsize=4096 blocks=13107200, imaxpct=25
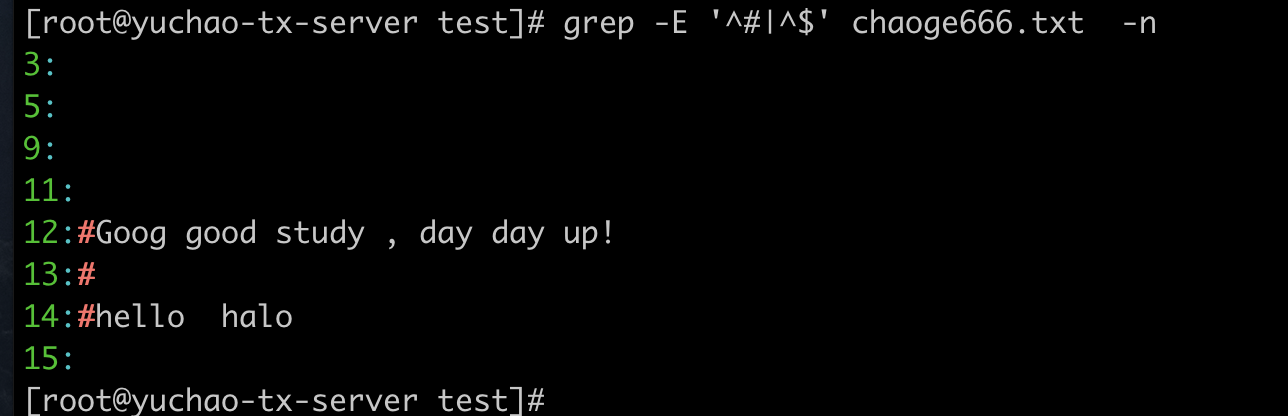
找出文件中的空行以及注释行
测试数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
[root@server test]# cat chaoge666.txt
I am teacher yuchao.
I teach linux,python!
I like english
My website is http://yuchaoit.cn
Our school site is https://apecome.com
My qq num is 877348180
my qq num is not 87777773333344444888811188880000
#Goog good study , day day up!
#
#hello halo
( ) 括号、分组符
1
2
3
4
5
6
7
8
9
语法
() 作用是将一个或者多个字符捆绑在一起,当做一个整体进行处理
小括号功能之一是分组过滤被括起来的内容,括号内的内容表示一个整体
括号()内的内容可以被后面的"\n"正则引用,n为数字,表示引用第几个括号的内容
\1:表示从左侧起,第一个括号中的模式所匹配到的字符
\2:从左侧起,第二个括号中的模式所匹配到的字符
分组基本用法
1
2
3
4
测试数据
[root@server test]# cat god.log
I am God, I need you to good good study and day day up, otherwise I will send you to see Gd,oh sorry, gooooooooood!
I am glad to see you, god,you are a good god!
要求仅仅匹配出glad和good
1
2
尝试使用正则
grep -iE "gla|ood" god.log

1
2
3
并非我们想要的数据
我想要的是例如这样的匹配,只找出good、glad
grep -iE "glad|good" god.log

可以使用分组写法
1
grep -iE "g(la|oo)d" god.log

分组与向后引用
1
2
3
4
5
6
语法
()
分组过滤,被括起来的内容表示一个整体,另外()的内容可以被后面的\n引用,n为数字,表示引用第几个括号的内容
\n
引用前面()里的内容,例如(abc)\1 表示匹配abcabc
测试数据
1
2
3
4
5
[root@server test]# cat lovers.log
I like my lover.
I love my lover.
He likes his lovers.
He love his lovers.
分组正则,提取love出现2次的行。
1
2
拆解
love,可以写为l..e

提取/etc/passwd
1
2
3
找出系统中几个特殊shell、专门用来开机,关机的用户
特点是、用户名、登录shell名字一样
可以用分区提取出
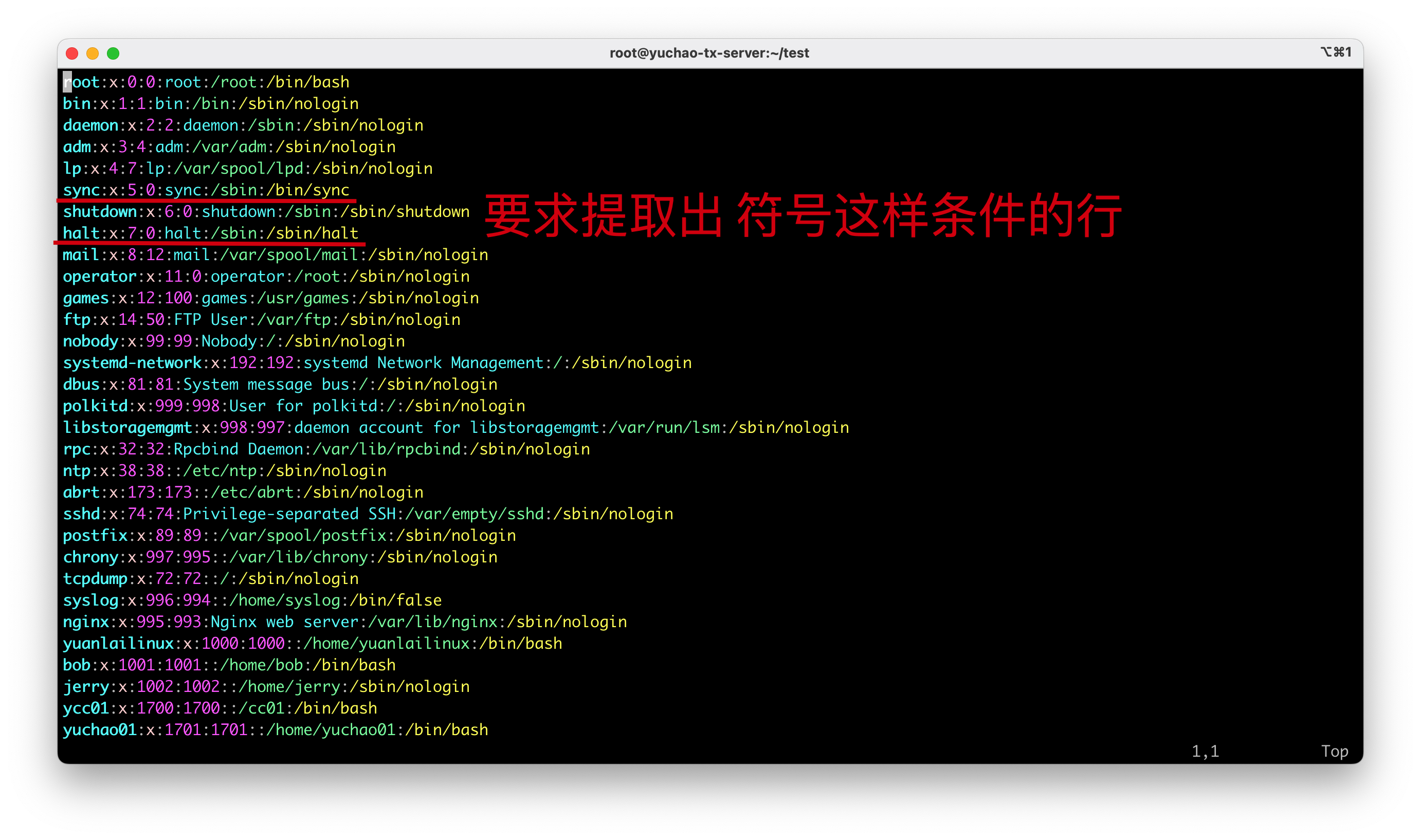
分组正则,提取特殊用户
1
2
3
4
5
6
7
8
9
这部分正则需要拆开,更容易理解
1.提取冒号以外的字符,使用+可以匹配更多字母,没必要每次只处理一个
grep -Ei "[^:]+" /etc/passwd
2. 使用\b匹配单词边界,提取出单词,示例用法,通常英文单词的边界是空格,标点符号
[root@server test]# echo 'my name is chao,everyone call me chaoge' | grep -Ei "chao\b" -o
chao
3.继续提取用户文件,来确定第一个单词的边界

完整图解

更简单的写法,多次分组

正则表达式总结
1
2
3
4
5
6
7
8
9
基础正则 BRE
^
$
.
*
.*
[abc]
[^abc]
\{n,m\}
BRE语法
1
2
.` 匹配单个任意字符, 匹配 `.` 本身使用 `\.
*` 前面的字符或模式重复任意次,匹配 `*` 本身使用 `\*
\{m\} 前面的字符或模式重复m次
\{m,n\} 前面的字符或模式重复m到n次
\{m,\} 前面的字符或模式重复m次及以上
\(regexp\) 分组,将 \( 和 \) 之间的内容视为一个整体,有两个作用
- 配合前面的
*\{m,n\}等量词使用,例如:ab\{2\}匹配“abb”, 而\(ab\)\{2\}匹配“abab” - 向后引用(back references),使用
\1~\9来引用第1~9个分组匹配的内容 - 例如:
\(ab*\)\1可以匹配“abab”,也能匹配“abbbabbb”
^ 放在正则表达式开头则匹配行首,其他位置匹配 ^ 本身
$ 放在正则表达式末尾则匹配行尾,其他位置匹配 $ 本身
[list] 自定义字符集,可以匹配 [ 和 ] 之间出现的任意字符,例如: a[bcd] 可以匹配”ab”,“ac”或“ad”。
且支持使用char1-char2这种省略写法,例如: [0-9]* 可以匹配”1234567890“ , [a-c]* 可以匹配“cabba”
[^list] 同上,^取反的作用,匹配所有没有出现在 [ 和 ] 之间的其他字符
1
另外其他风格的正则表达式中有诸如 \d \w \s 等速记符号(shorthand)表示一些常用字符集,BER和ERE均不支持这种写法,取而代之的是POSIX标准中定义的字符集:
POSIX正则语法表
| POSIX | Description | ASCII | Shorthand |
|---|---|---|---|
| [:alnum:] | 数字和字母 | [a-zA-Z0-9] | |
| [:alpha:] | 字母 | [a-zA-Z] | |
| [:ascii:] | ASCII字符 | [\x00-\x7F] | |
| [:blank:] | 空格和 Tab | [ \t] | \h |
| [:cntrl:] | 控制字符 | [\x00-\x1F\x7F] | |
| [:digit:] | 数字 | [0-9] | \d |
| [:graph:] | 可视字符 | [\x21-\x7E] | |
| [:lower:] | 小写字母 | [a-z] | \l |
| [:print:] | 可打印字符 | [\x20-\x7E] | |
| [:punct:] | 标点符号 | [!”#$%&’()*+, -./:;<=>?@[ ]^_‘{\ | }~] |
| [:space:] | 所有空白字符 | [ \t\r\n\v\f] | \s |
| [:upper:] | 大写字母 | [A-Z] | \u |
| [:word:] | 单词 | [A-Za-z0-9_] | \w |
| [:xdigit:] | 十六进制数 | [A-Fa-f0-9] |
1
注意:[ 和 ] 也是该字符集名称的一部分,即在使用中和 [0-9] 等价的是 [[:digit:]] 而不是 [:digit:]
ERE语法
ERE和BRE的最显著的区别是ERE中所有元字符(metacharacters)均不需要使用 \ 进行转义,即用 {m,n} 替代 \{m,n\} , (regexp) 替代 \(regexp\) (当然分组向后引用依旧是 \1 ~ \9)。
此外ERE还在BRE基础上增加了以下语法:
? 前面的字符或模式重复0或1次
+ 前面的字符或模式重复1次及以上
|,regexp1 | regexp2匹配regexp1或regexp2 |
GNU扩展的BRE
实际上现代Linux发行版中使用的 grep sed awk 等工具均由GNU提供,GNU在实现时对BRE进行了扩展,增加了 \? \+ \| 使得BRE和ERE的区别仅剩元字符是否需要转义。
个人认为BRE现在存在的主要意义还是向下兼容,避免修改已经投入使用的正则表达式。
正则官网讲解
参考官网文档,拿到最精准的解释
- https://www.regular-expressions.info/posix.html
- https://www.regular-expressions.info/posixbrackets.html
- https://www.gnu.org/software/sed/manual/html_node/BRE-syntax.html#BRE-syntax
总结grep
- egrep被淘汰,使用grep -E
- 可以是用grep -o参数,查看每次匹配的结果
- 正则需要在练习中理解其含义,无法死记硬背
- 后面结合sed、awk发挥更多正则作用
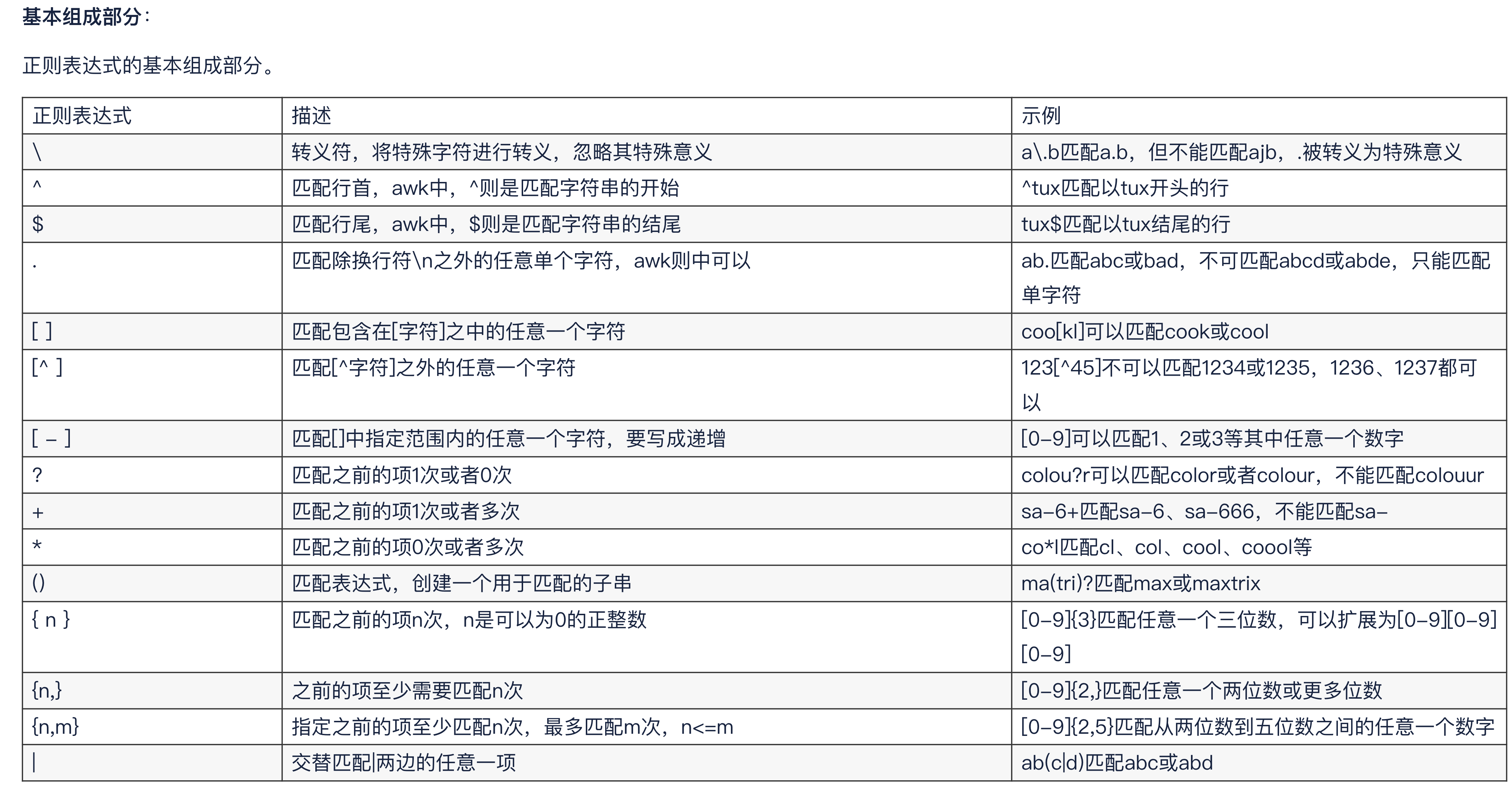
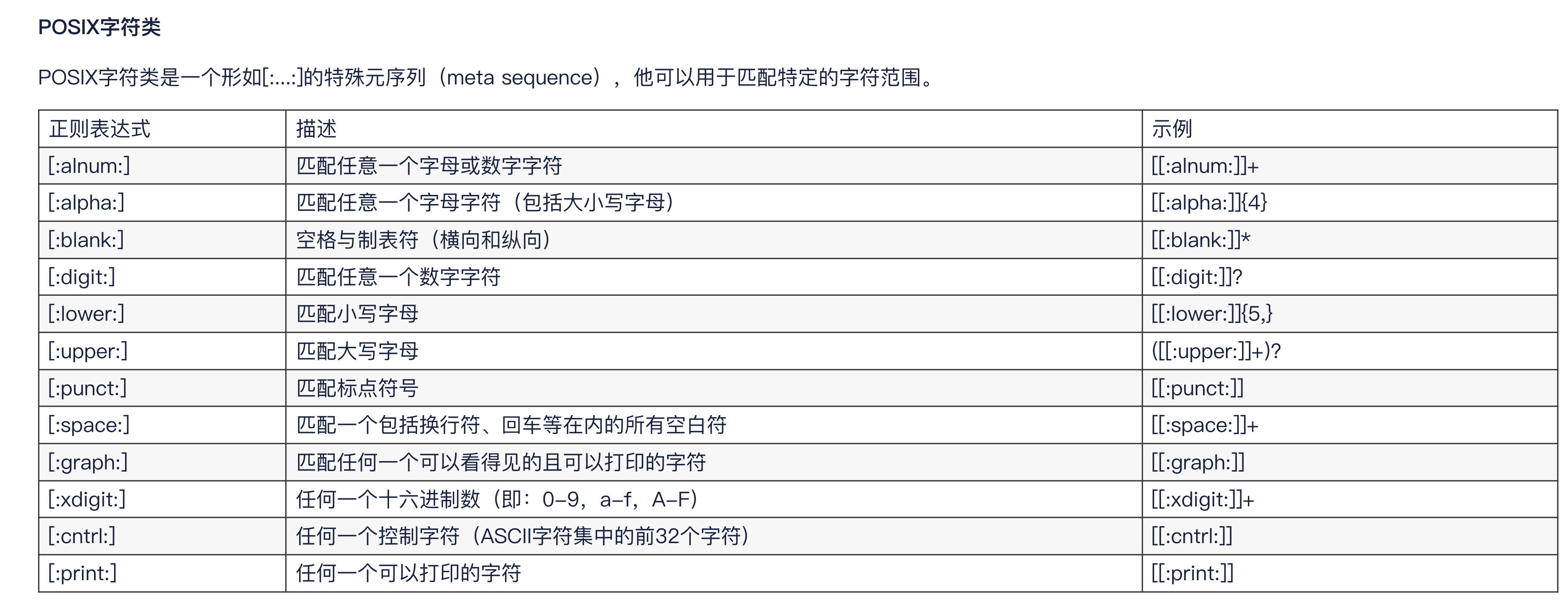
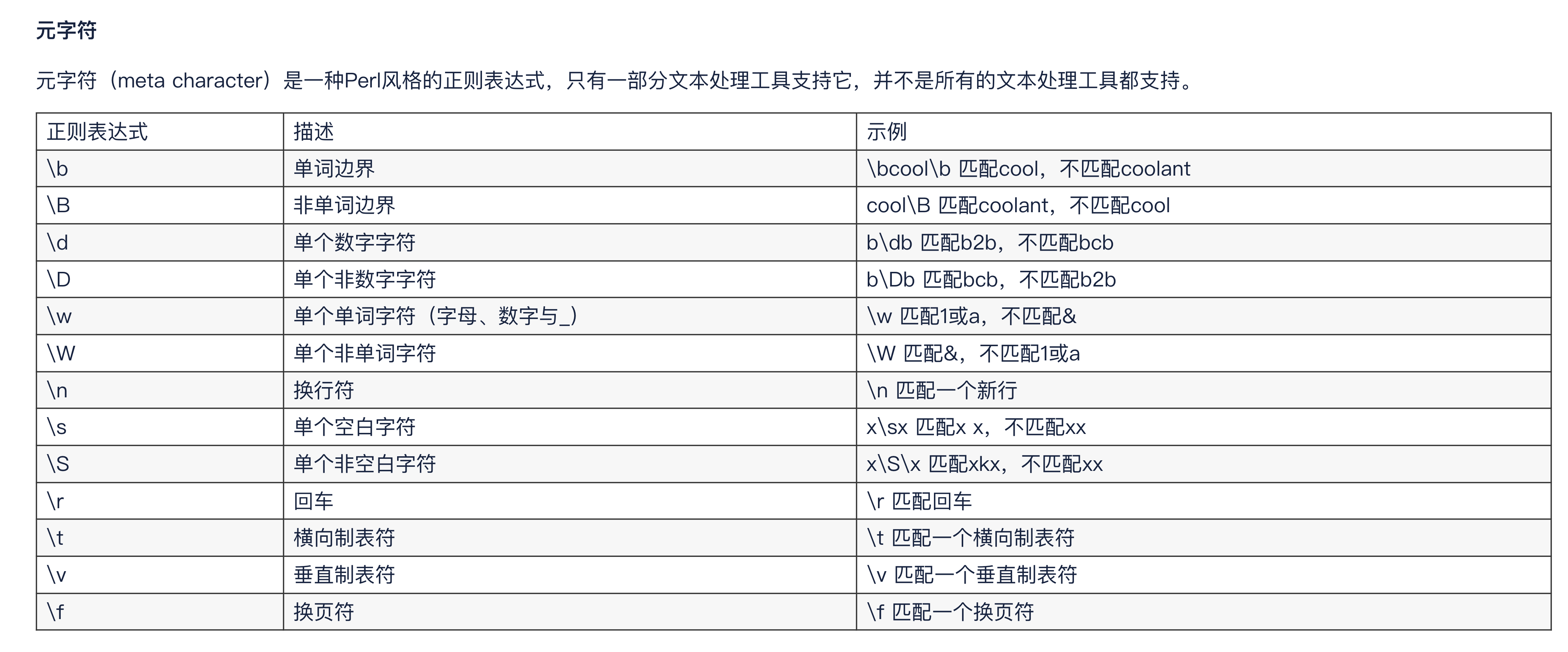
正则记忆表
可以用于在线测试正则的网站https://deerchao.cn/tools/wegester/